Estimated reading time: 5 minutes
Introduction
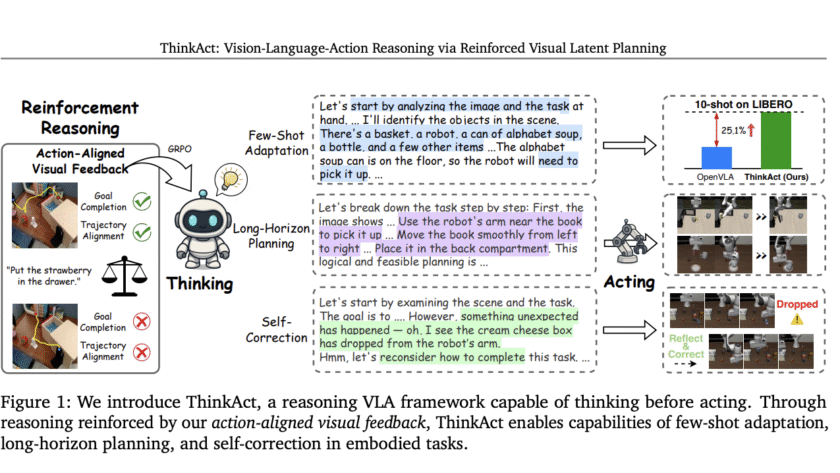
Embodied AI agents are increasingly being called upon to interpret complex, multimodal instructions and act robustly in dynamic environments. ThinkAct, presented by researchers from Nvidia and National Taiwan University, offers a breakthrough for vision-language-action (VLA) reasoning, introducing reinforced visual latent planning to…