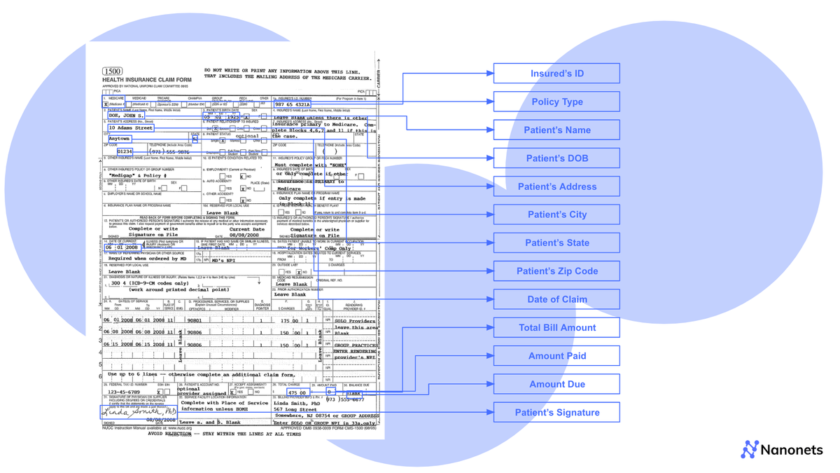
Data annotation is the process of labeling data available in video, text, or images. Labeled datasets are required for supervised machine learning so that machines can clearly understand the input patterns. In autonomous mobility, annotated datasets are essential for training self-driving vehicles to recognize and respond to road conditions, traffic signs, and potential hazards. In…
Read More