
Scientific publication
T. M. Lange, M. Gültas, A. O. Schmitt & F. Heinrich (2025). optRF: Optimising random forest stability by determining the optimal number of trees. BMC bioinformatics, 26(1), 95. Follow this LINK to the original publication.
Random Forest — A Powerful Tool for Anyone Working With Data
What is Random Forest?
Have you ever wished you…
Survival Analysis is a statistical approach used to answer the question: “How long will something last?” That “something” could range from a patient’s lifespan to the durability of a machine component or the duration of a user’s subscription.
One of the most widely used tools in this area is the Kaplan-Meier estimator.
Born in the…
It’s well known that what we eat matters — but what if when and how often we eat matters just as much?
In the midst of ongoing scientific debate around the benefits of intermittent fasting, this question becomes even more intriguing. As someone passionate about machine learning and healthy living, I was inspired by a 2017 research paper[1] exploring this intersection. The…
Why you should read this
As someone who did a Bachelors in Mathematics I was first introduced to L¹ and L² as a measure of Distance… now it seems to be a measure of error — where have we gone wrong? But jokes aside, there seems to be this misconception that L₁ and L₂ serve the same function — and…
Artificial intelligence (AI) capabilities and autonomy are growing at an accelerated pace in Agentic Ai, escalating an AI alignment problem. These rapid advancements require new methods to ensure that AI agent behavior is aligned with the intent of its human creators and societal norms. However, developers and data scientists first need an understanding of the…
The recent launch of the DeepSeek-R1 model sent ripples across the global AI community. It delivered breakthroughs on par with the reasoning models from Meta and OpenAI, achieving this in a fraction of the time and at a significantly lower cost.
Beyond the headlines and online buzz, how can we assess the model’s reasoning abilities…
Deploying your Large Language Model (LLM) is not necessarily the final step in productionizing your Generative AI application. An often forgotten, yet crucial part of the MLOPs lifecycle is properly load testing your LLM and ensuring it is ready to withstand your expected production traffic. Load testing at a high level is the practice of…

Recently, Sesame AI published a demo of their latest Speech-to-Speech model. A conversational AI agent who is really good at speaking, they provide relevant answers, they speak with expressions, and honestly, they are just very fun and interactive to play with.
Note that a technical paper is not out yet, but they do have a…
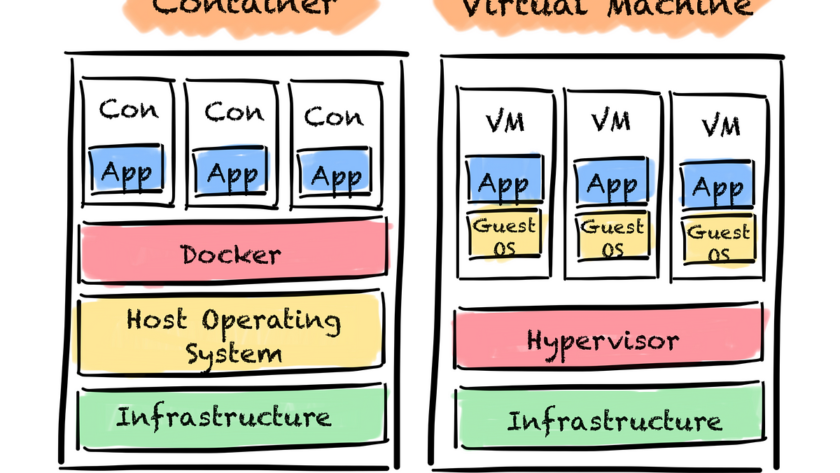
For a ML model to be useful it needs to run somewhere. This somewhere is most likely not your local machine. A not-so-good model that runs in a production environment is better than a perfect model that never leaves your local machine.
However, the production machine is usually different from the one you developed the…
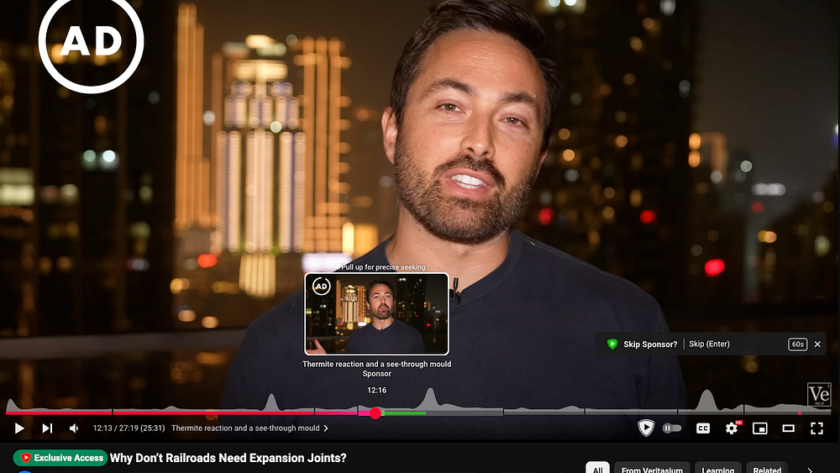
I’m definitely not the only person who feels that YouTube sponsor segments have become longer and more frequent recently. Sometimes, I watch videos that seem to be trying to sell me something every couple of seconds.
On one hand, it’s great that both small and medium-sized YouTubers are able to make a living from their…