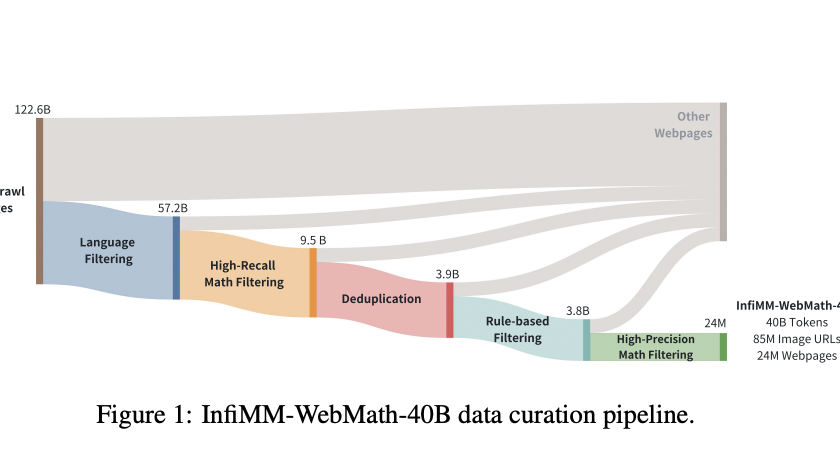
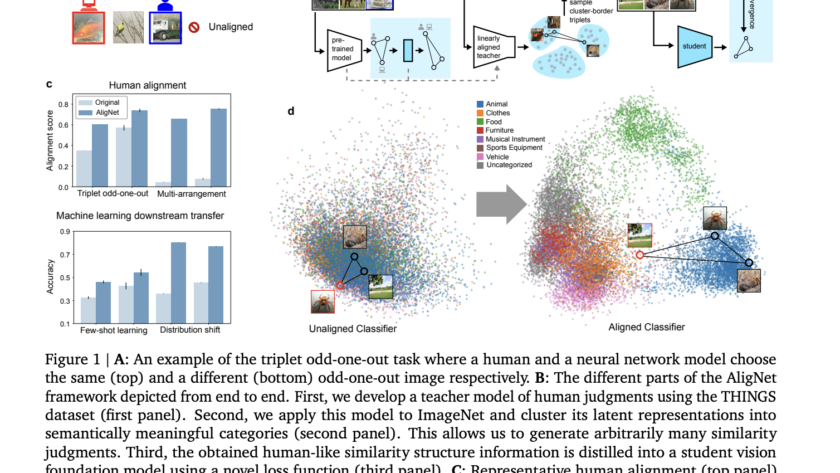
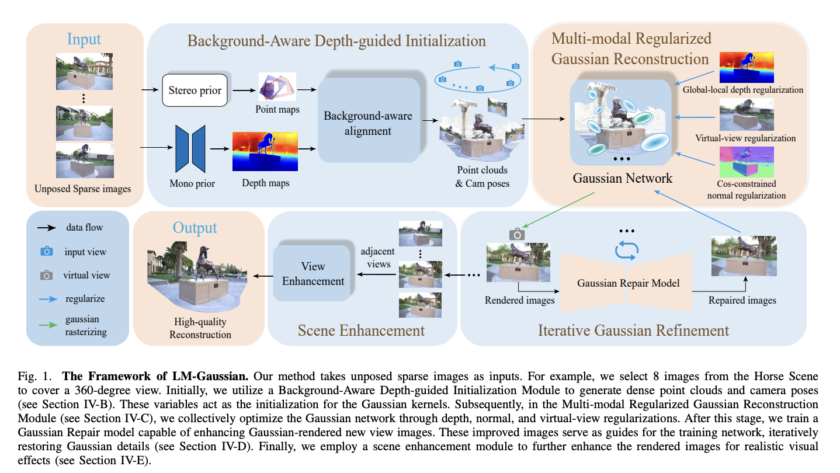
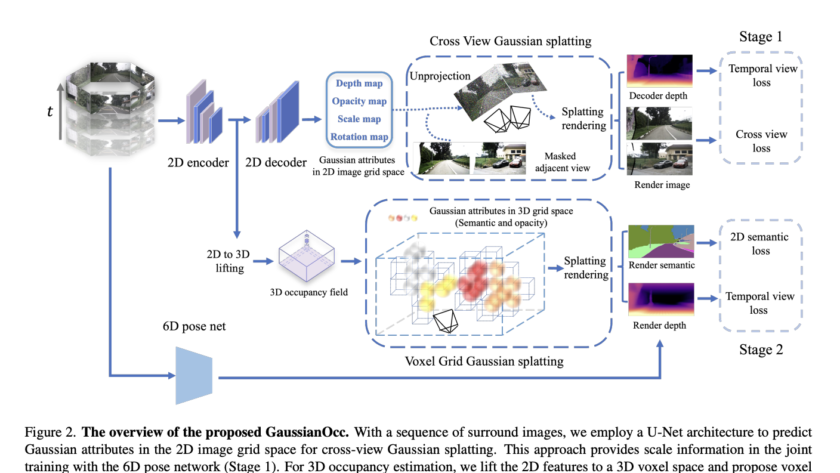
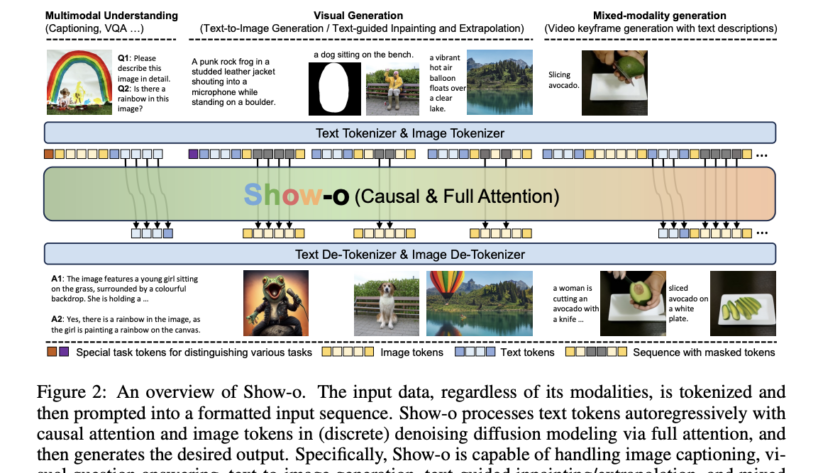
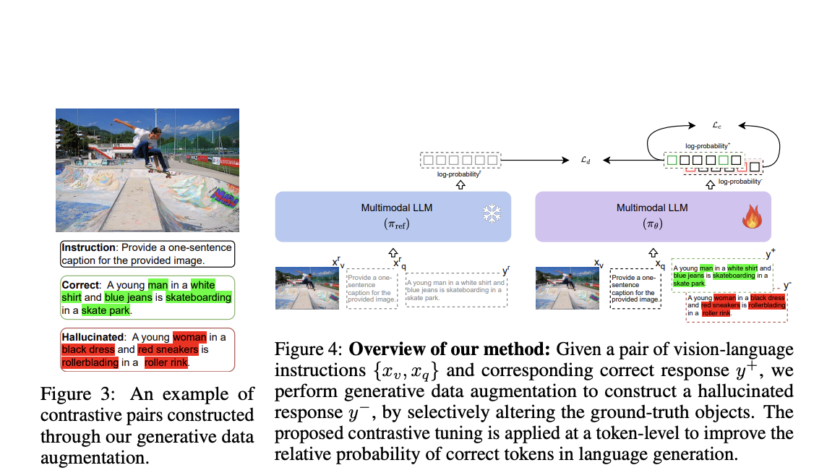
Artificial intelligence has significantly enhanced complex reasoning tasks, particularly in specialized domains such as mathematics. Large Language Models (LLMs) have gained attention for their ability to process large datasets and solve intricate problems. The mathematical reasoning capabilities of these models have vastly improved over the years. This progress has been driven by advancements in training…