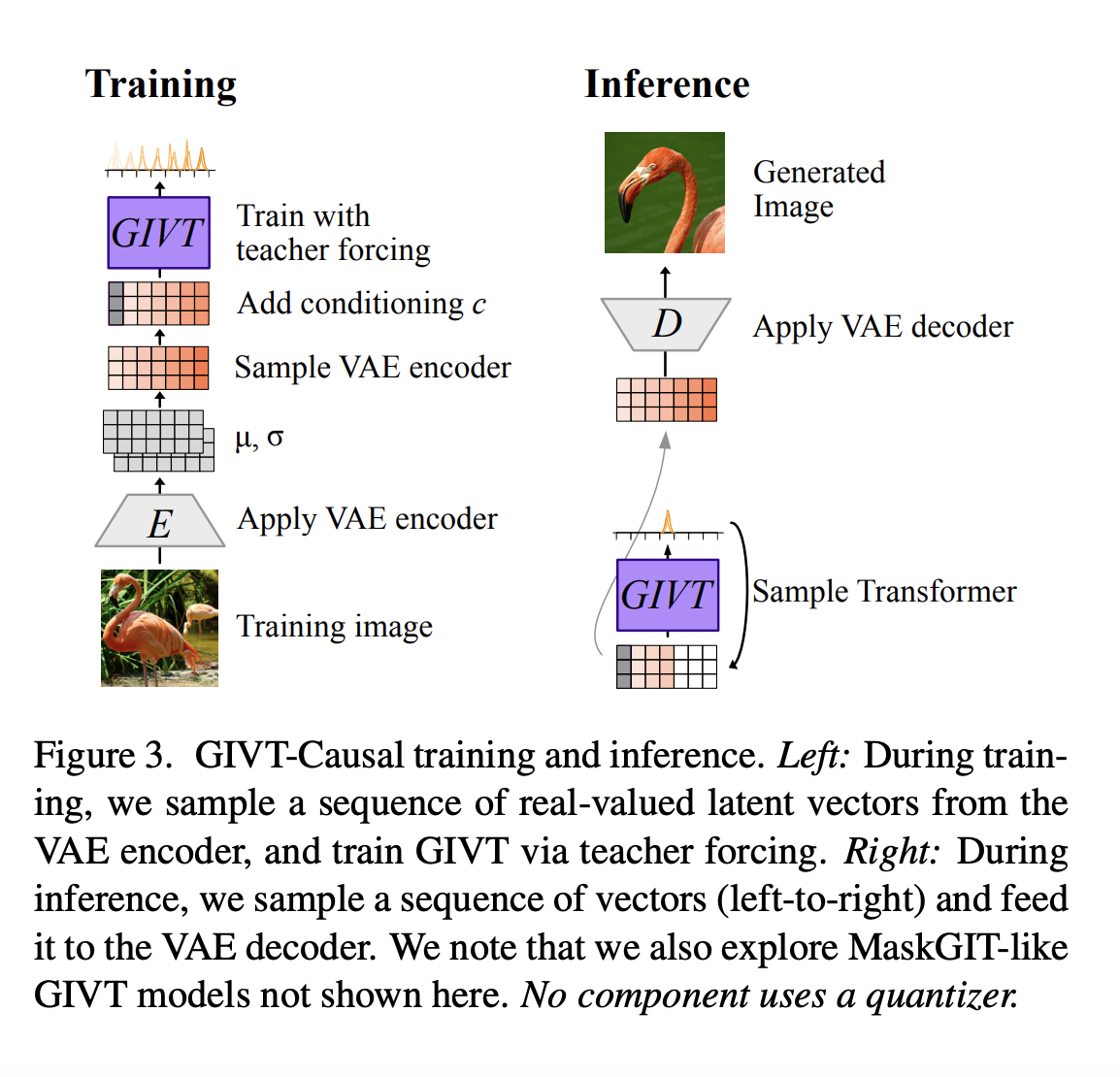
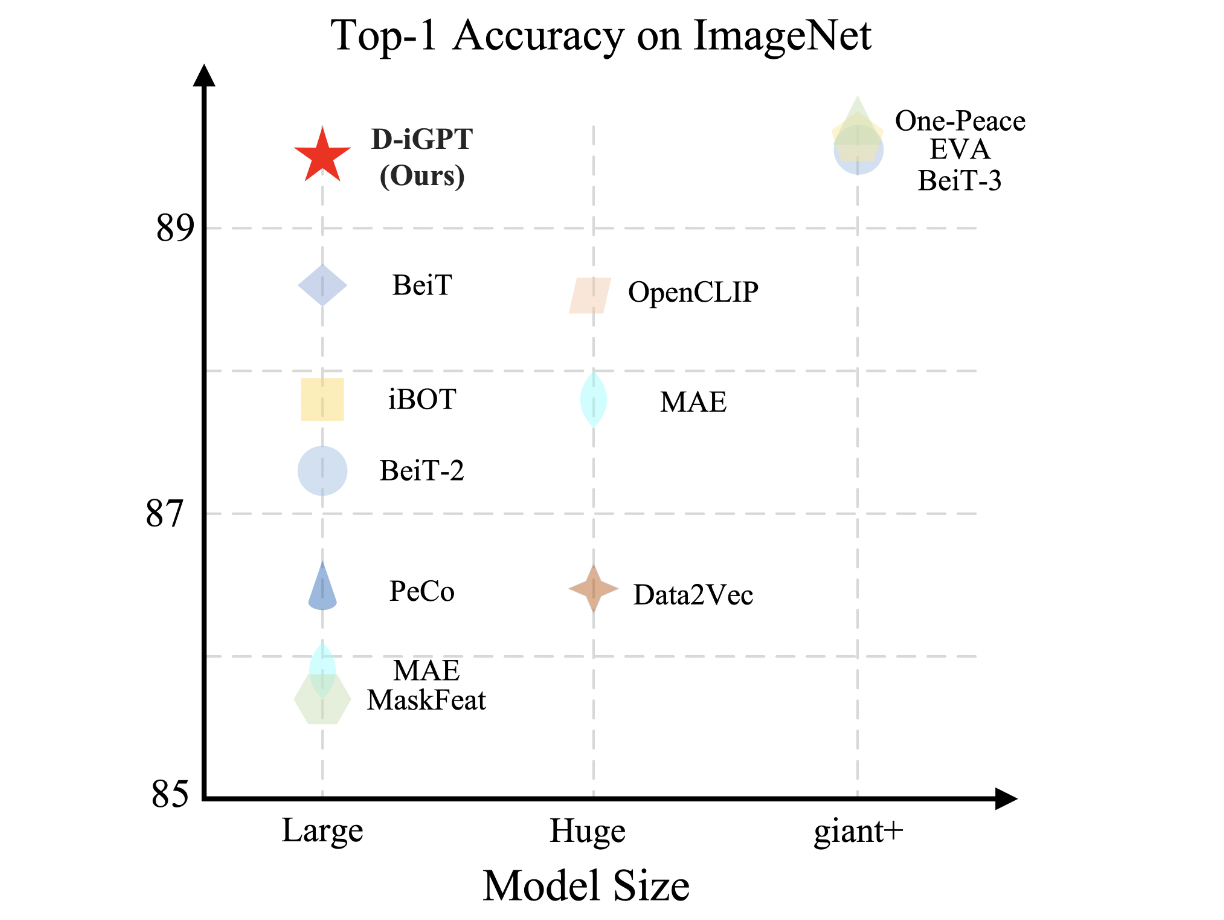
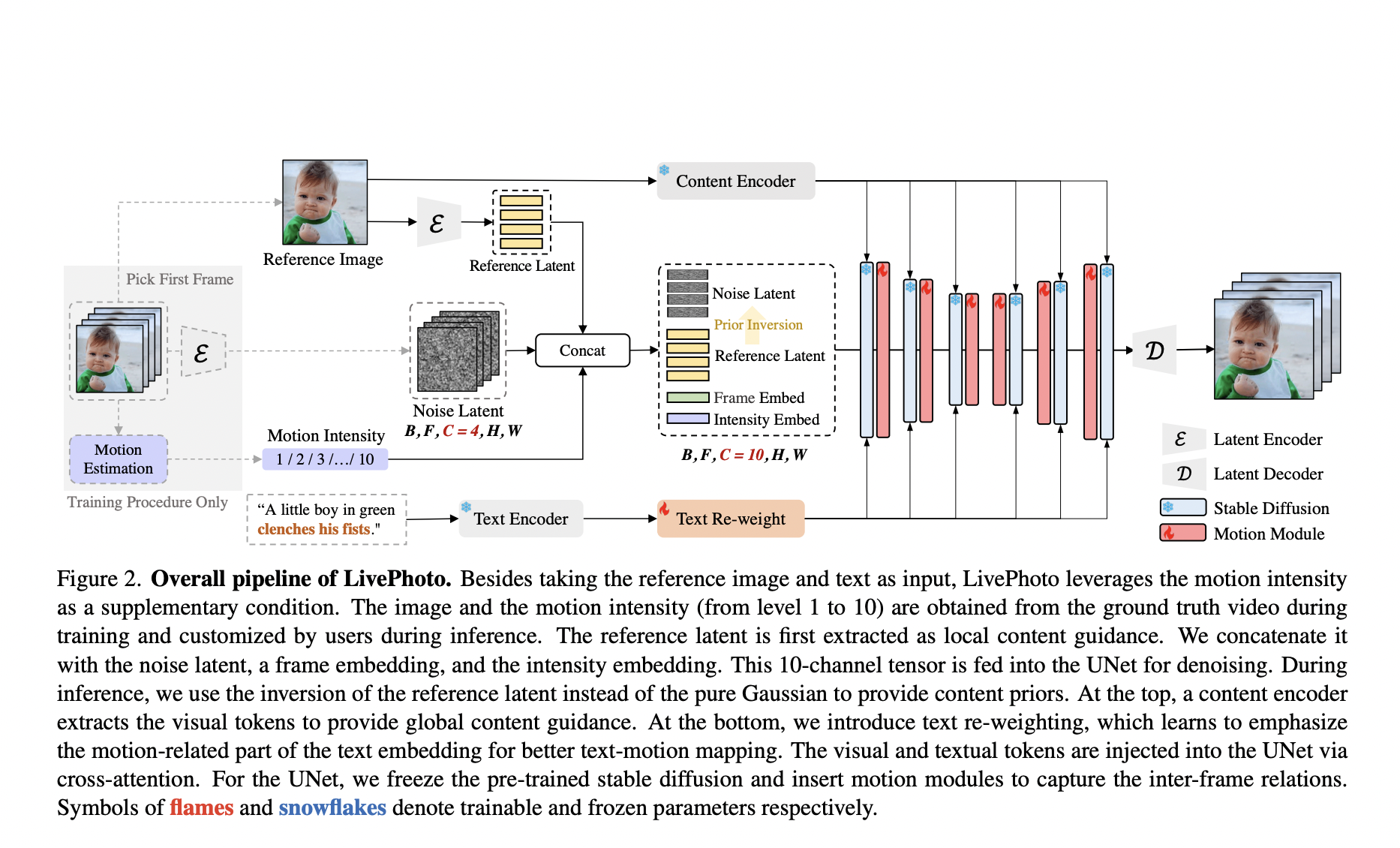
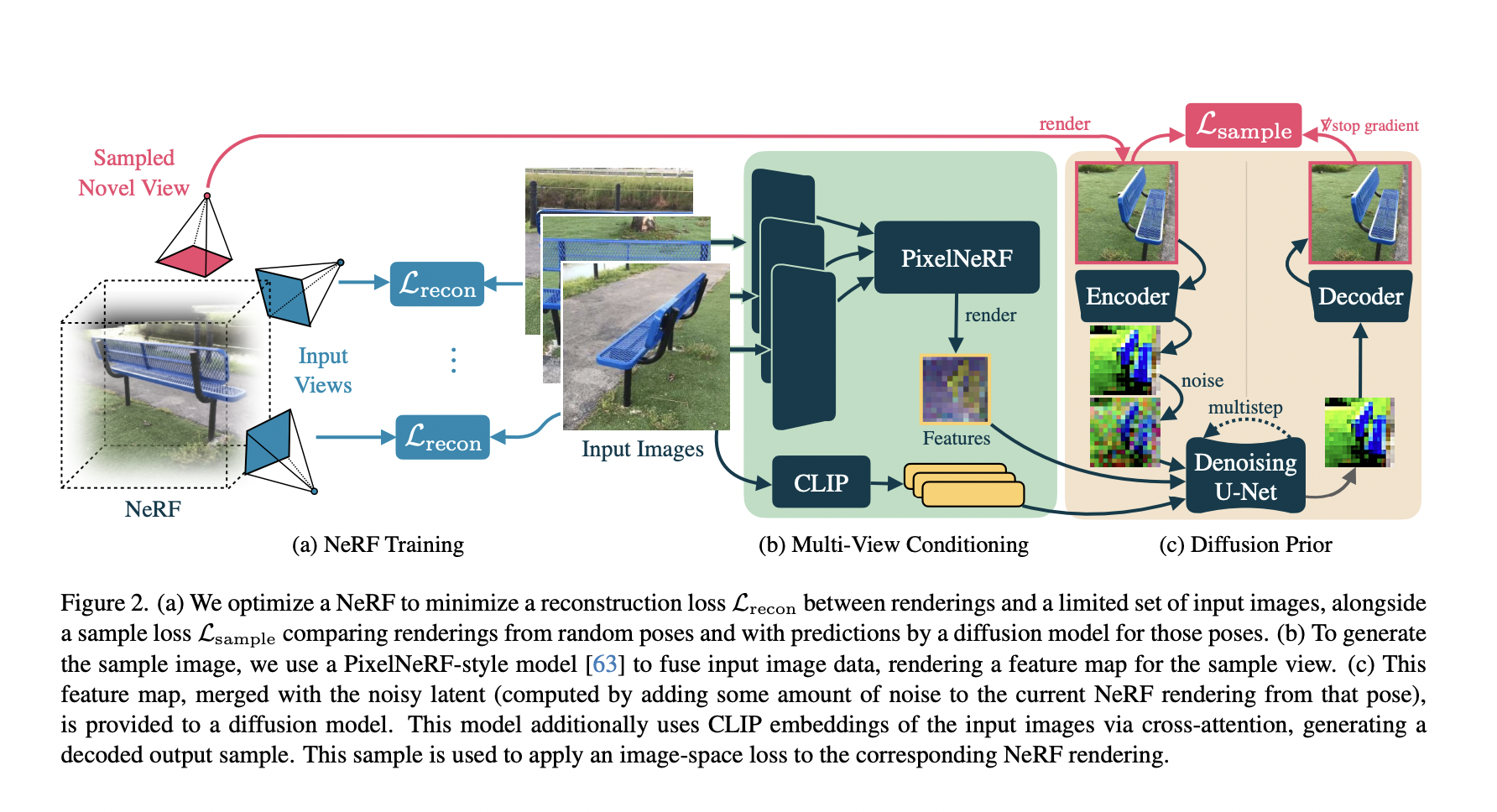
Volumetric recording and realistic representation of 4D (spacetime) human performance dissolve the barriers between spectators and performers. It offers a variety of immersive VR/AR experiences, such as telepresence and tele-education. Some early systems use nonrigid registration explicitly to recreate textured models from recorded footage. However, they are still susceptible to occlusions and texture deficiencies, which…