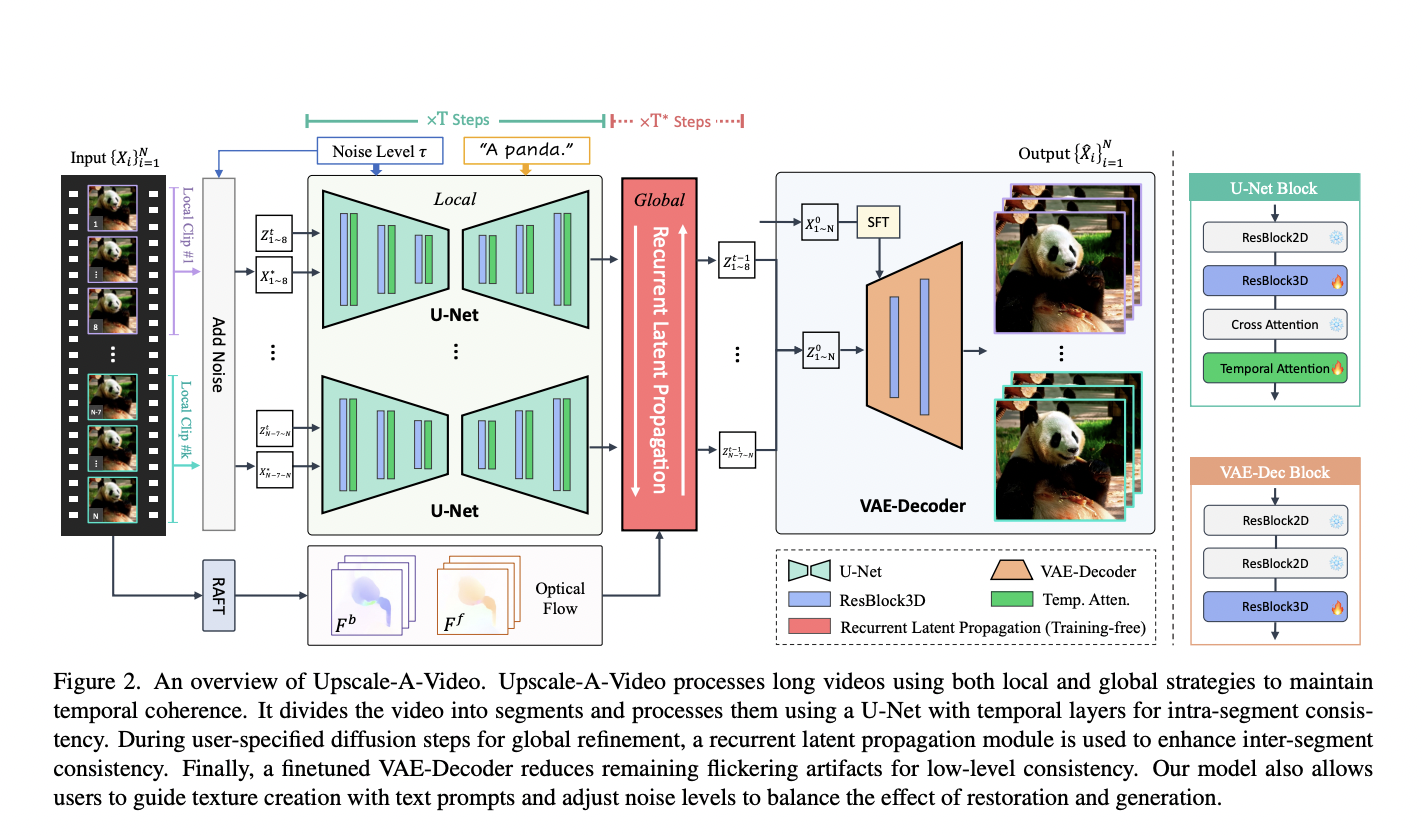
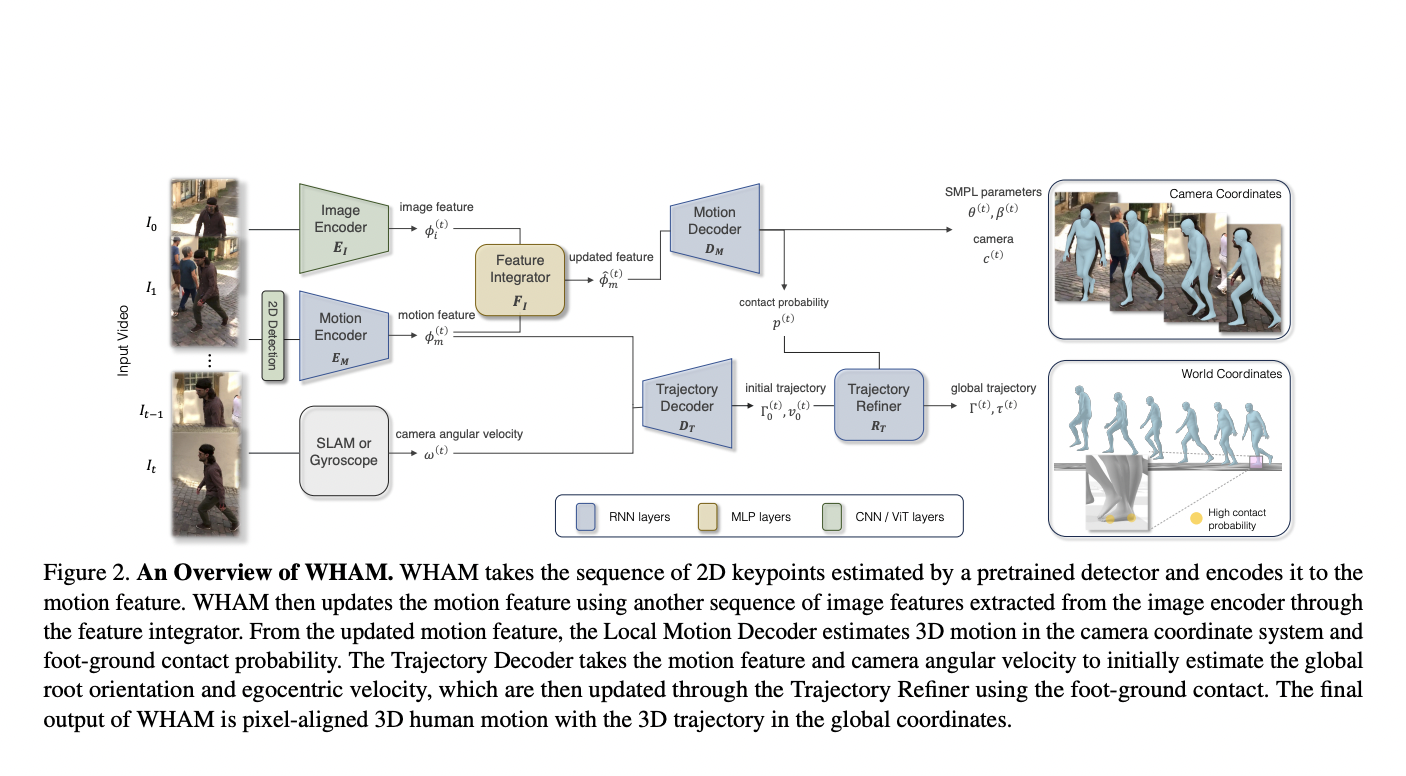
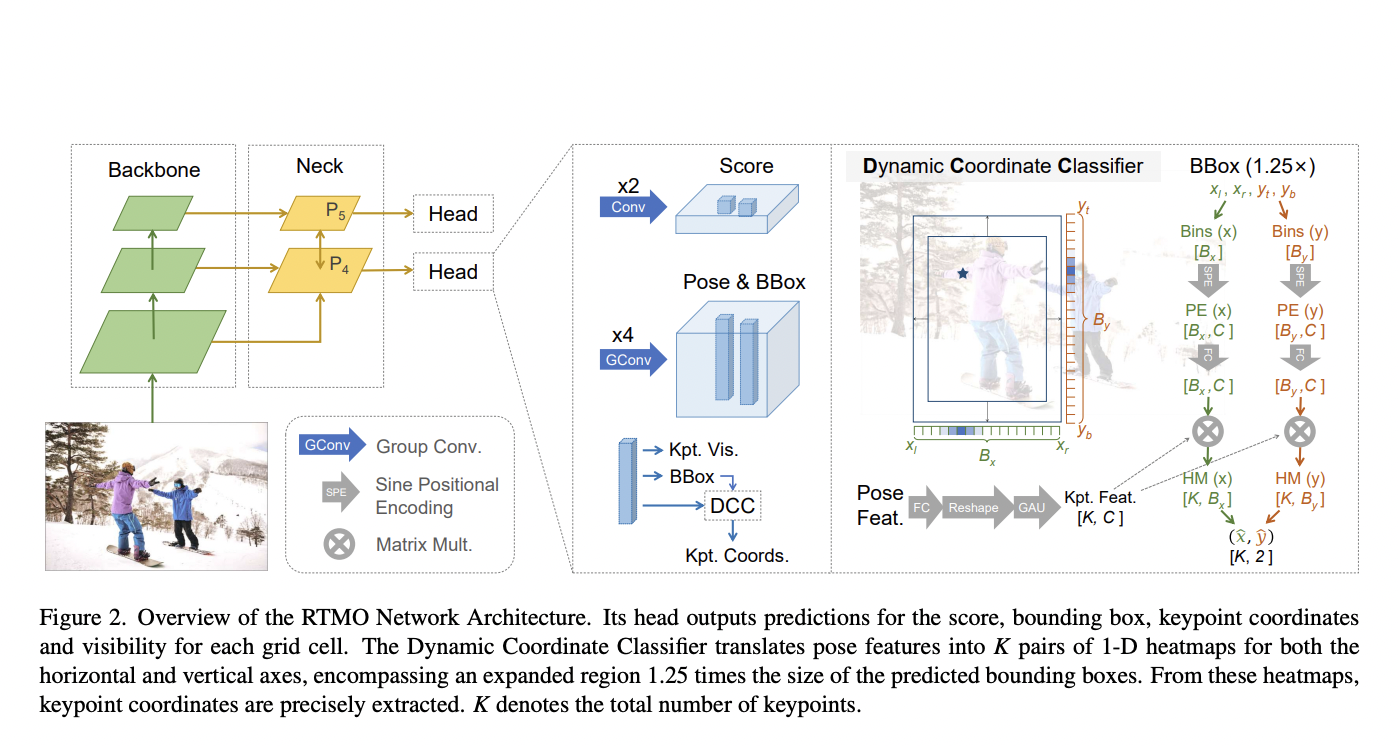
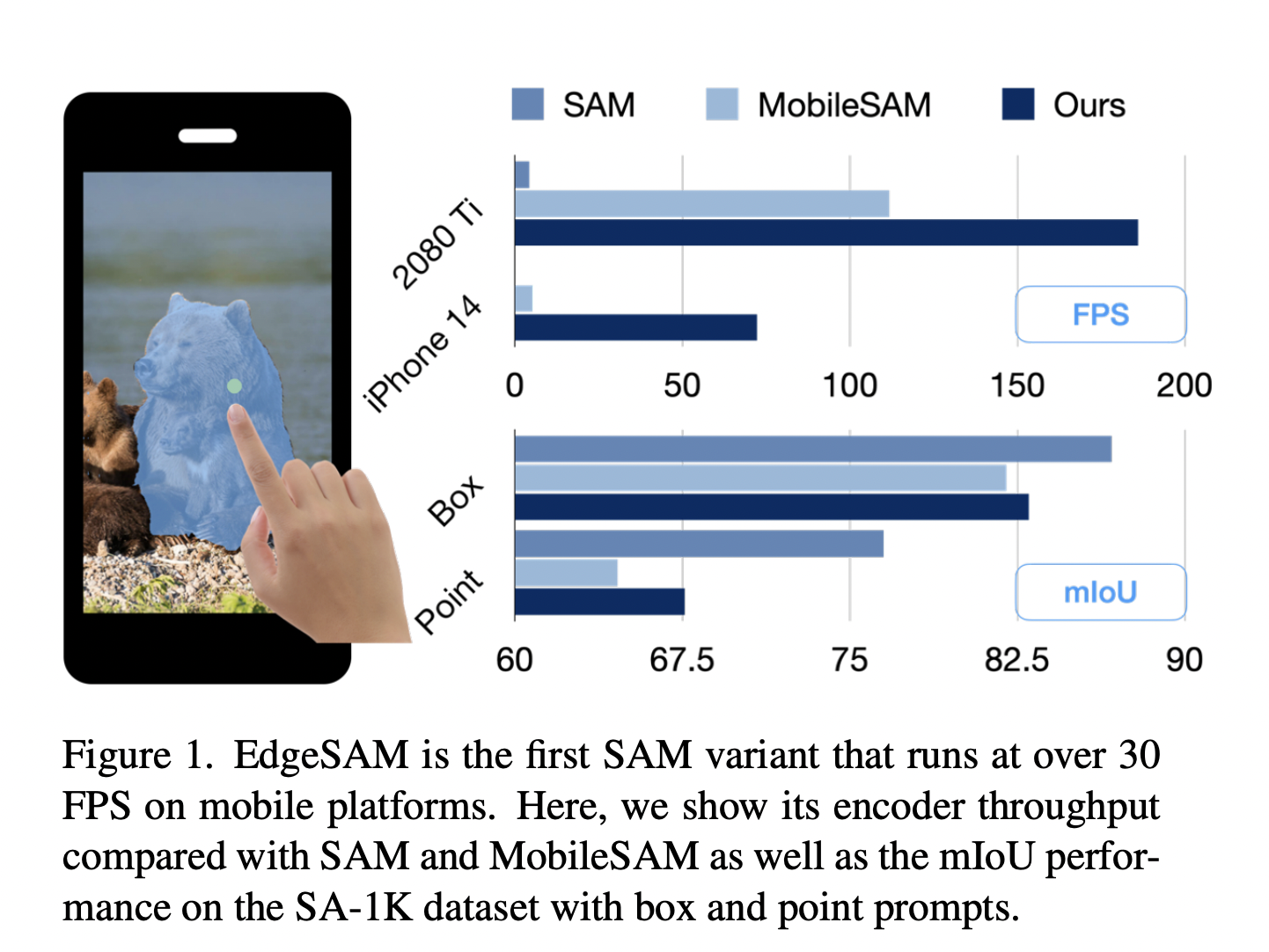
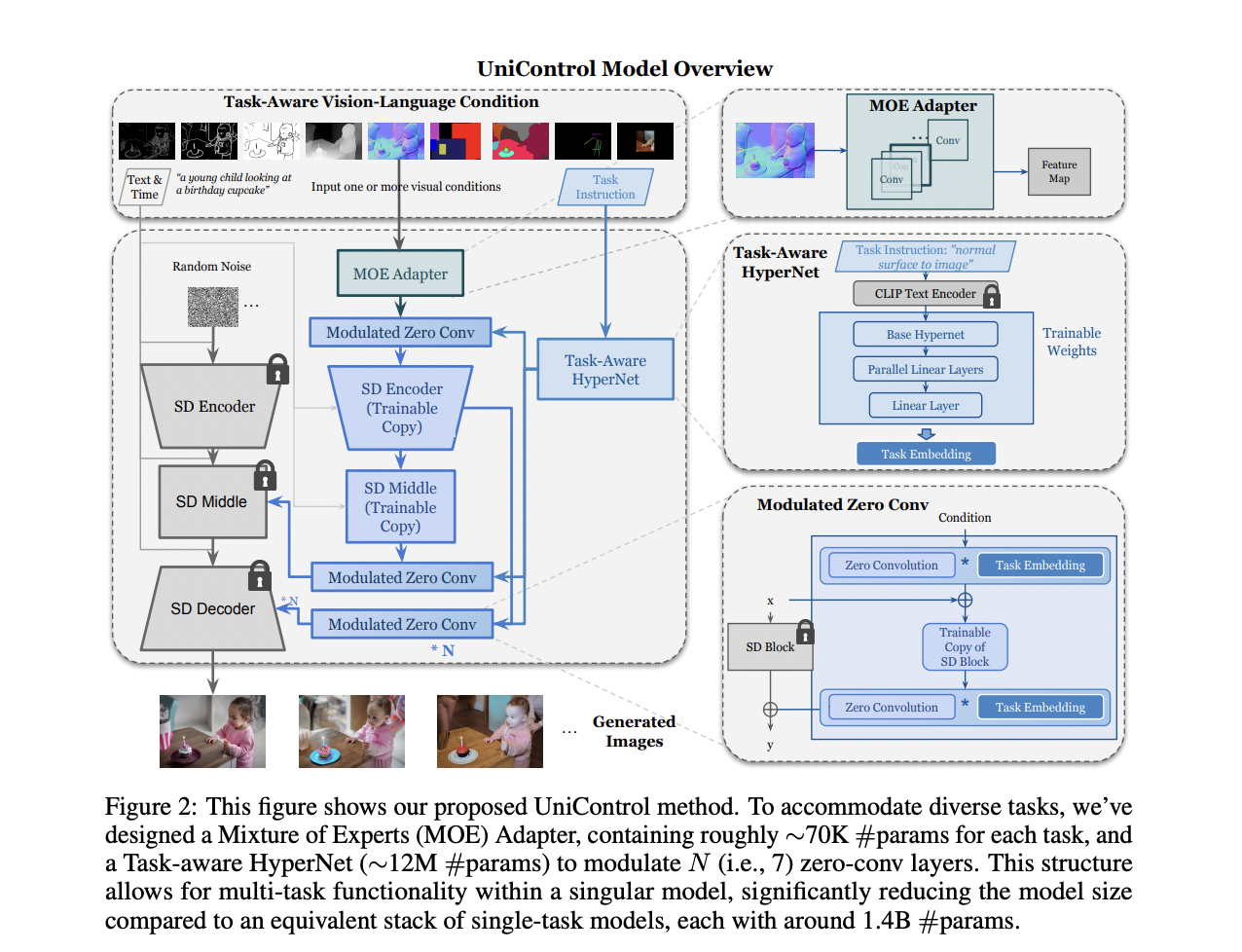
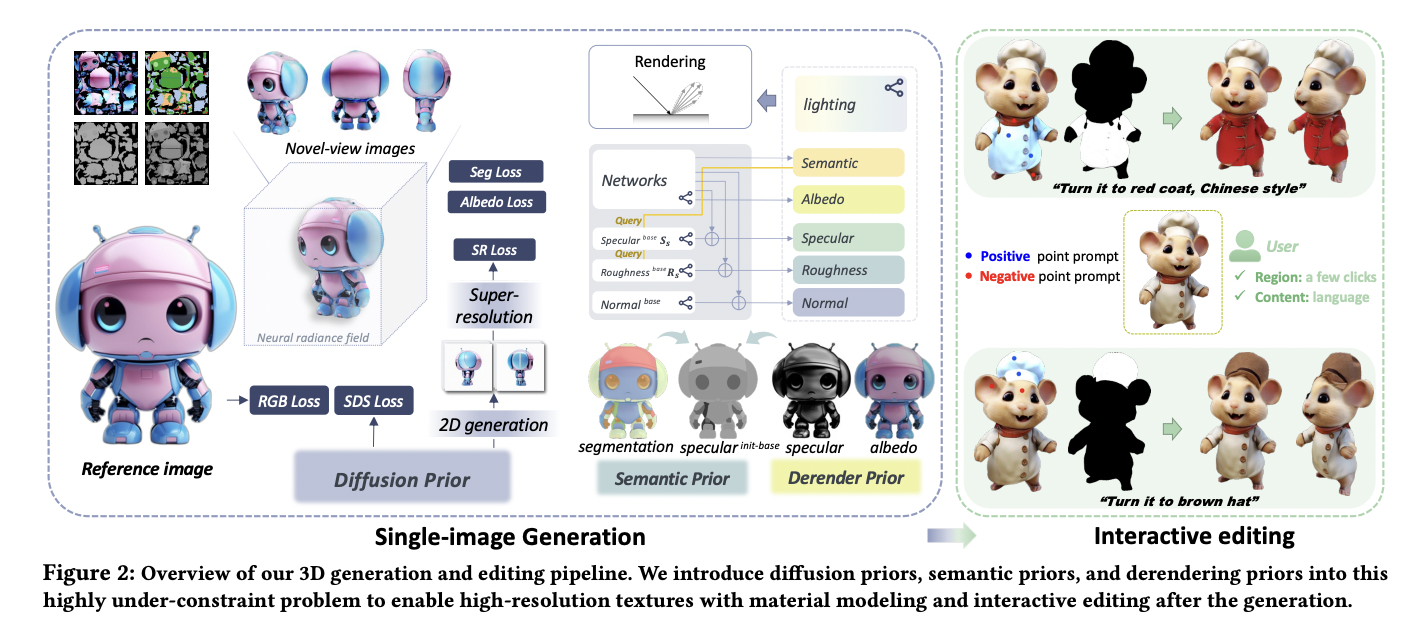
Video super-resolution, aiming to elevate the quality of low-quality videos to high fidelity, faces the daunting challenge of addressing diverse and intricate degradations commonly found in real-world scenarios. Unlike previous focuses on synthetic or specific camera-related degradations, the complexity arises from multiple unknown factors like downsampling, noise, blur, flickering, and video compression. While recent CNN-based…