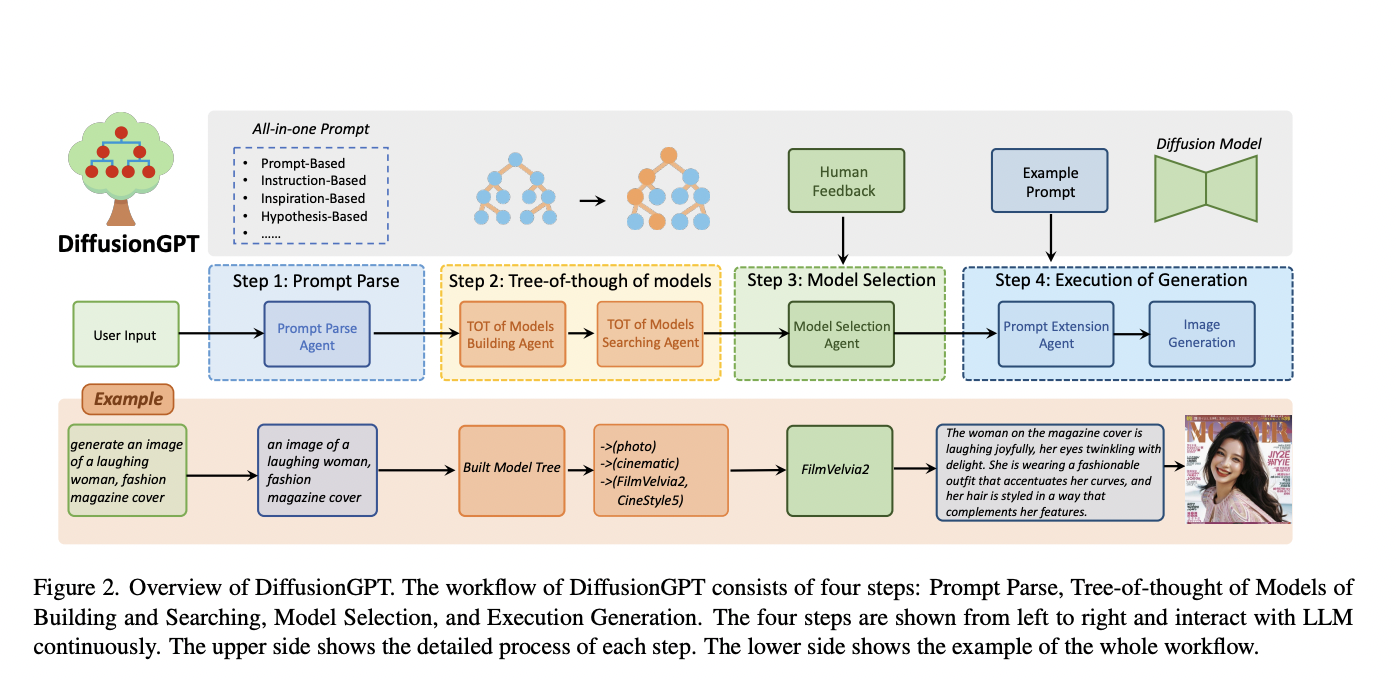
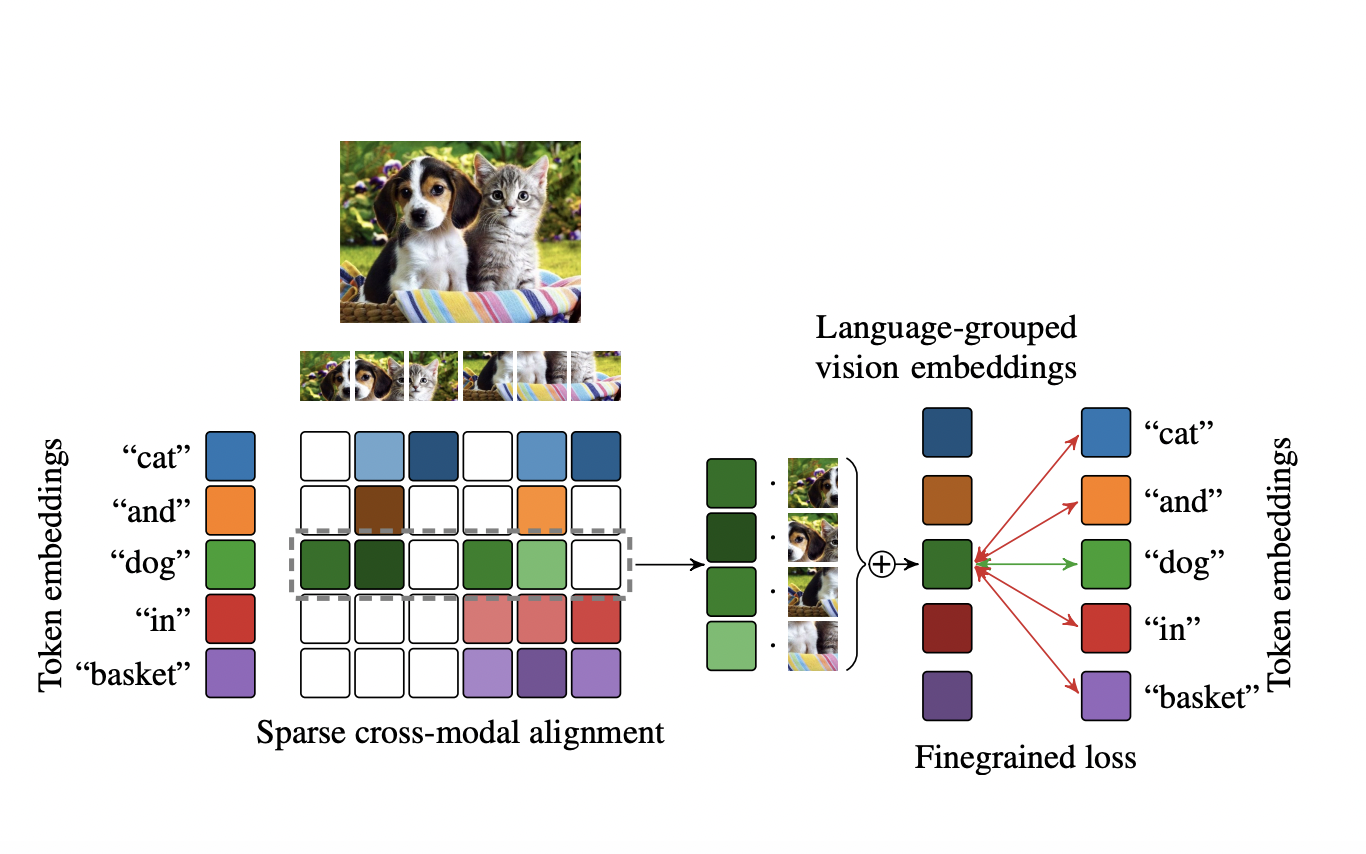
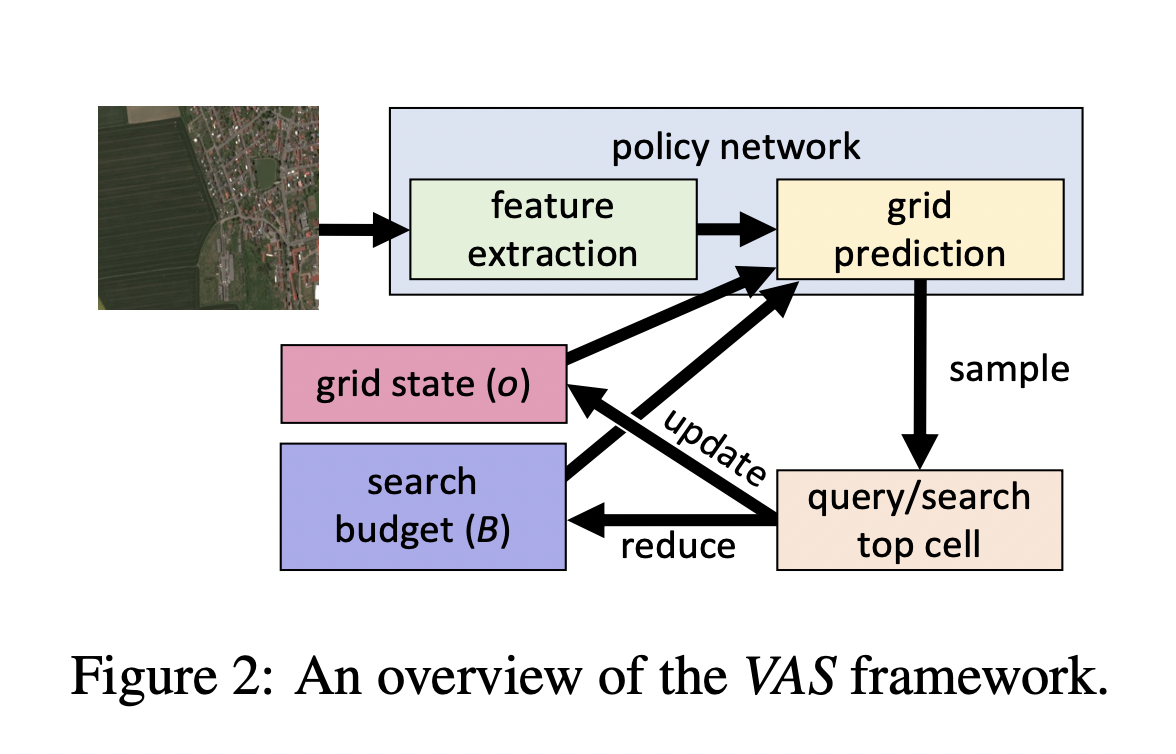
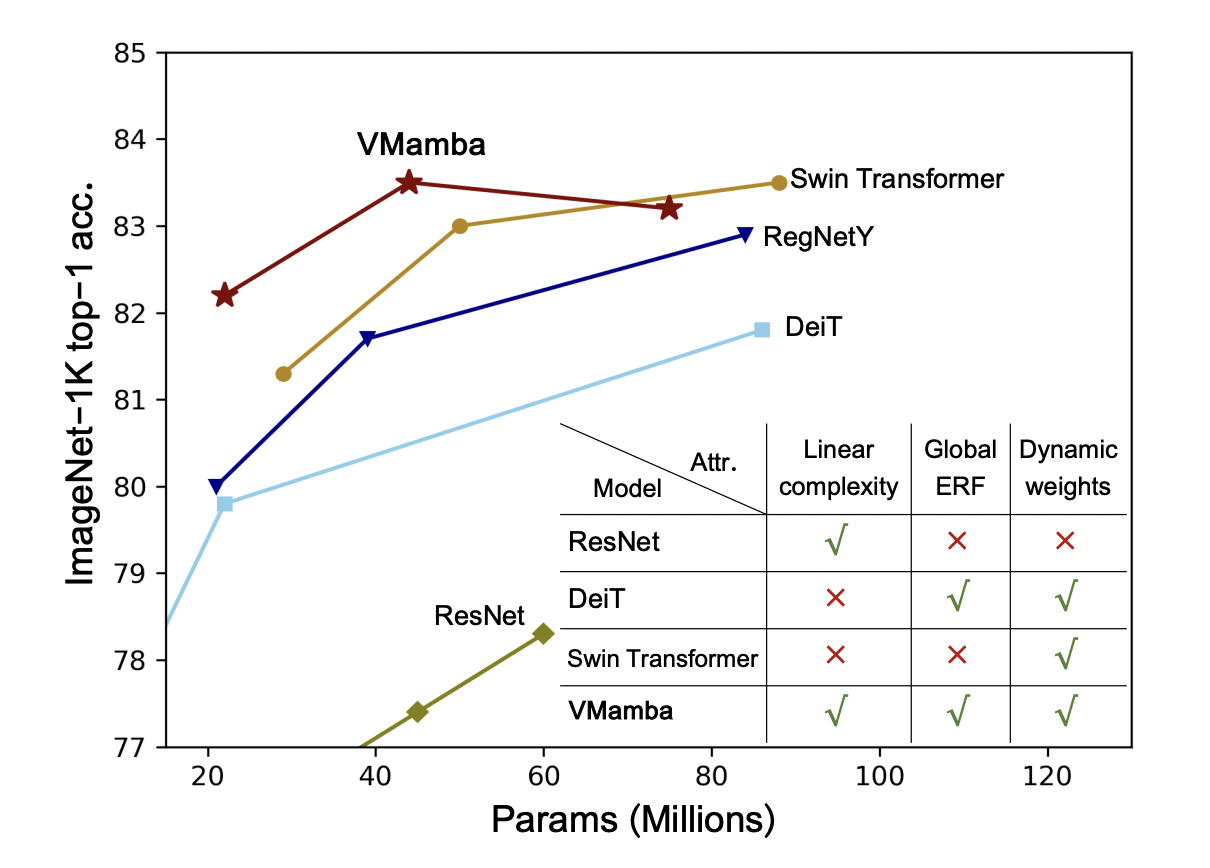
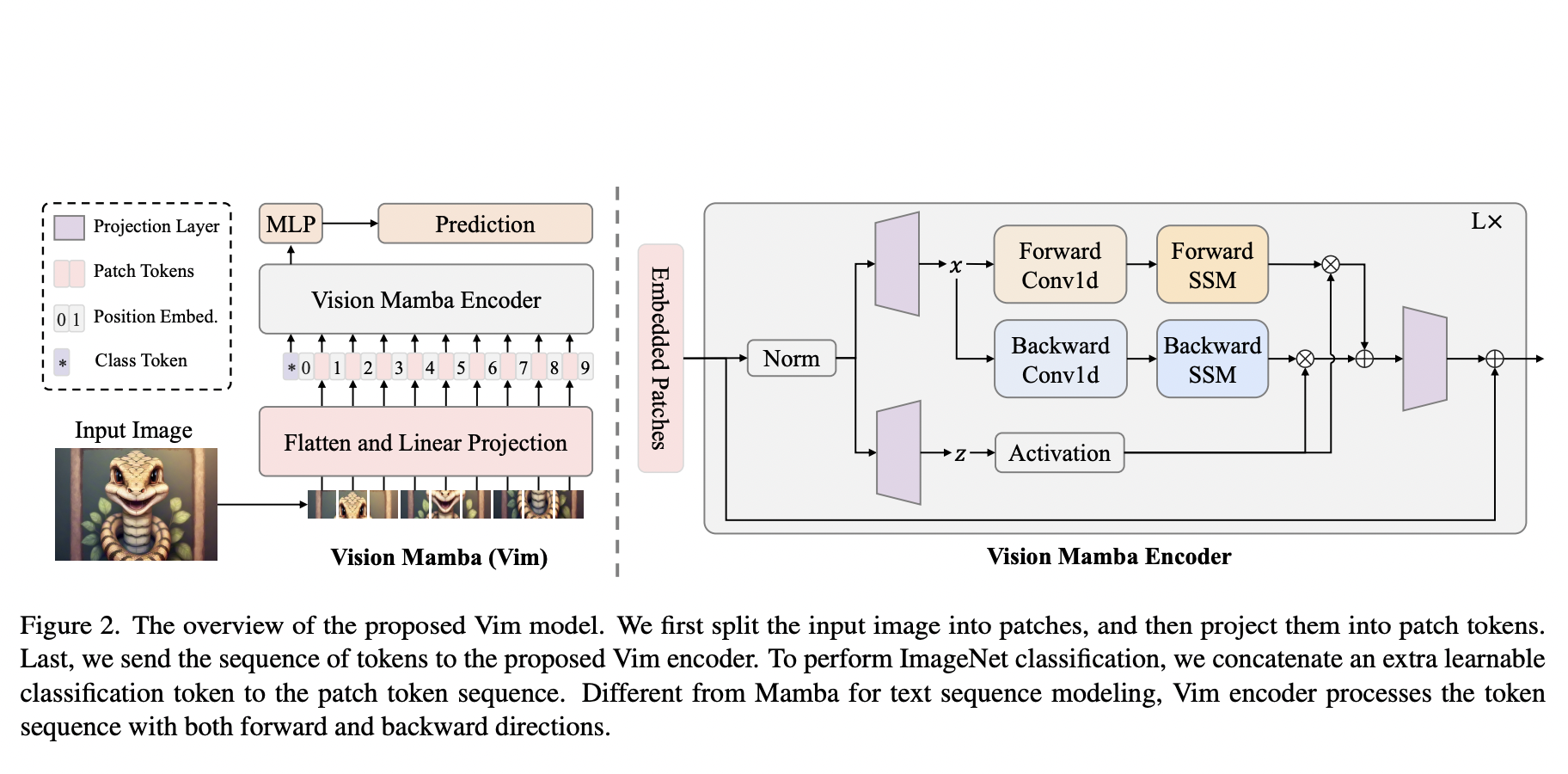
In image generation, diffusion models have significantly advanced, leading to the widespread availability of top-tier models on open-source platforms. Despite these strides, challenges in text-to-image systems persist, particularly in managing diverse inputs and being confined to single-model outcomes. Unified efforts commonly address two distinct facets: first, the parsing of various prompts during the input stage,…