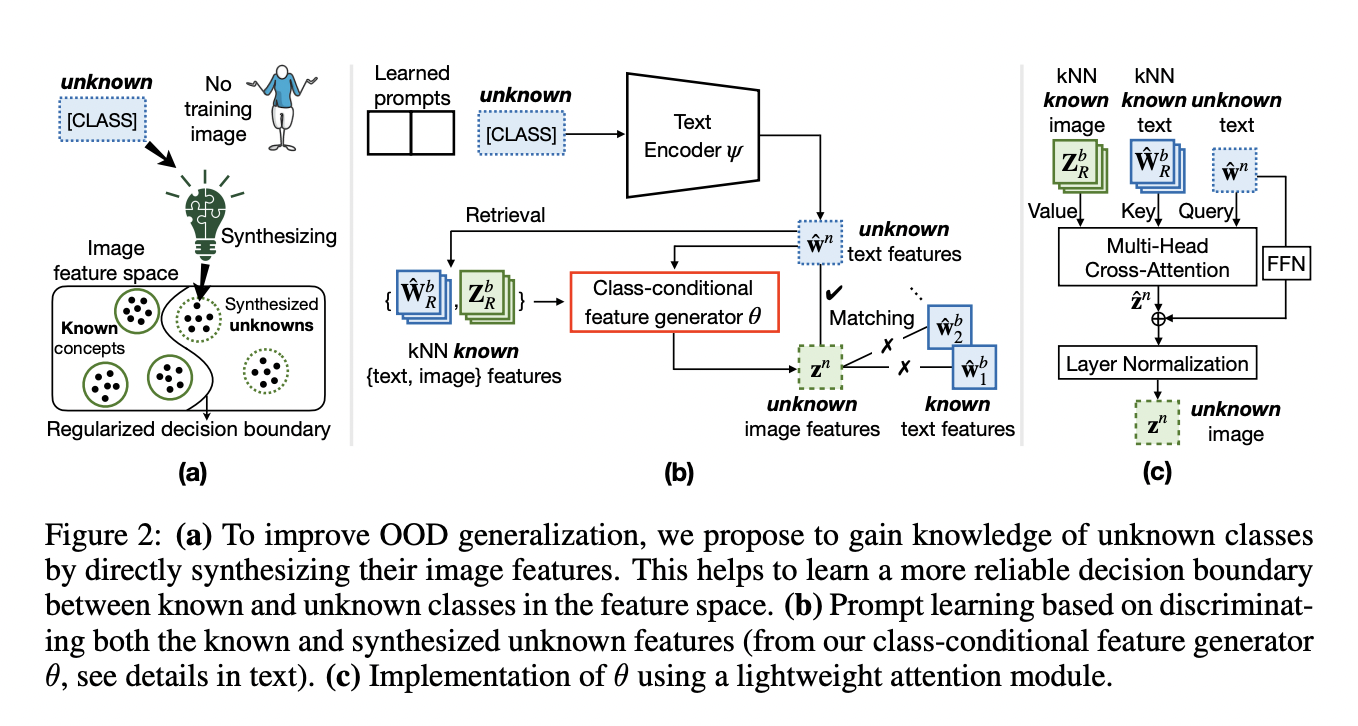
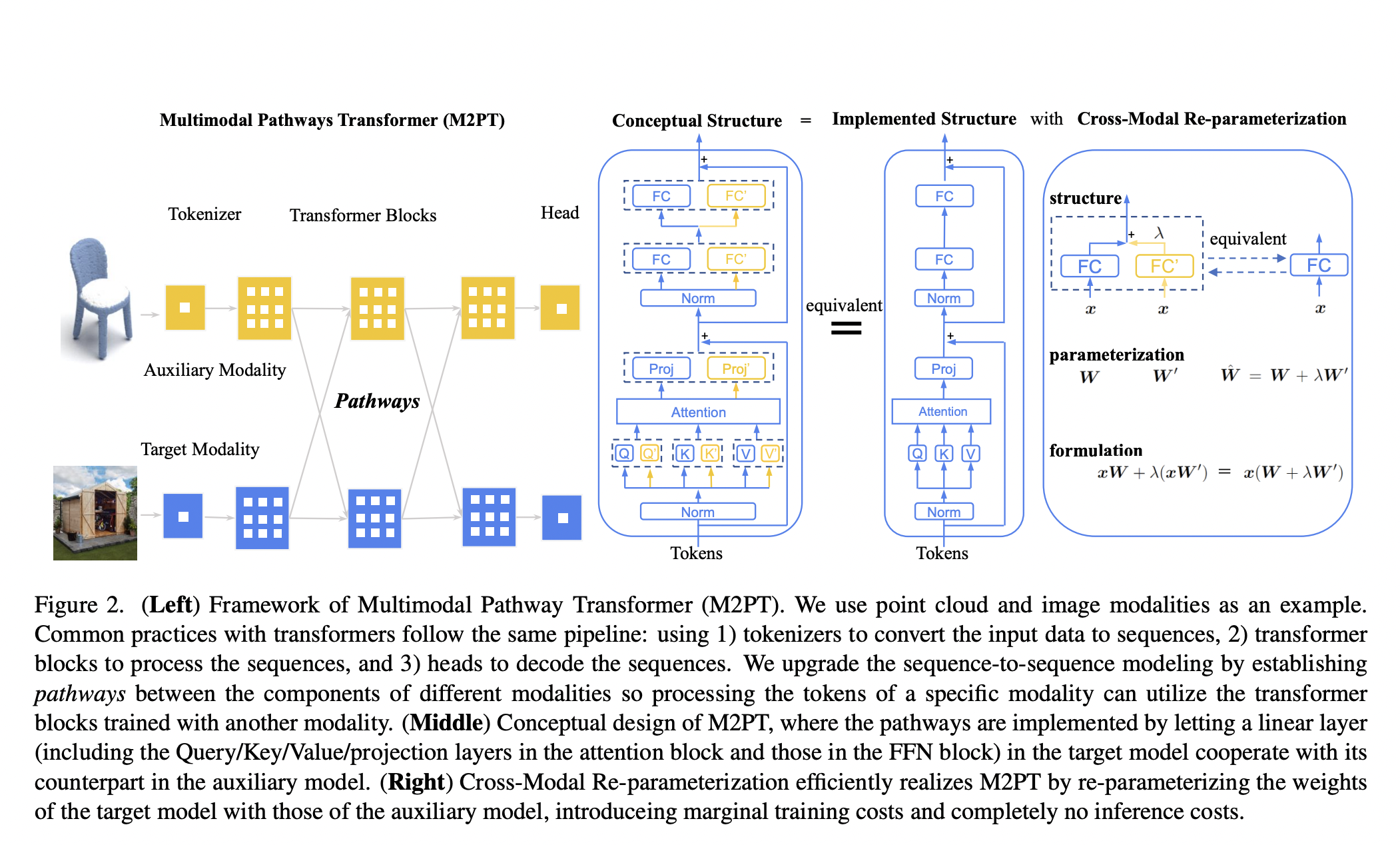
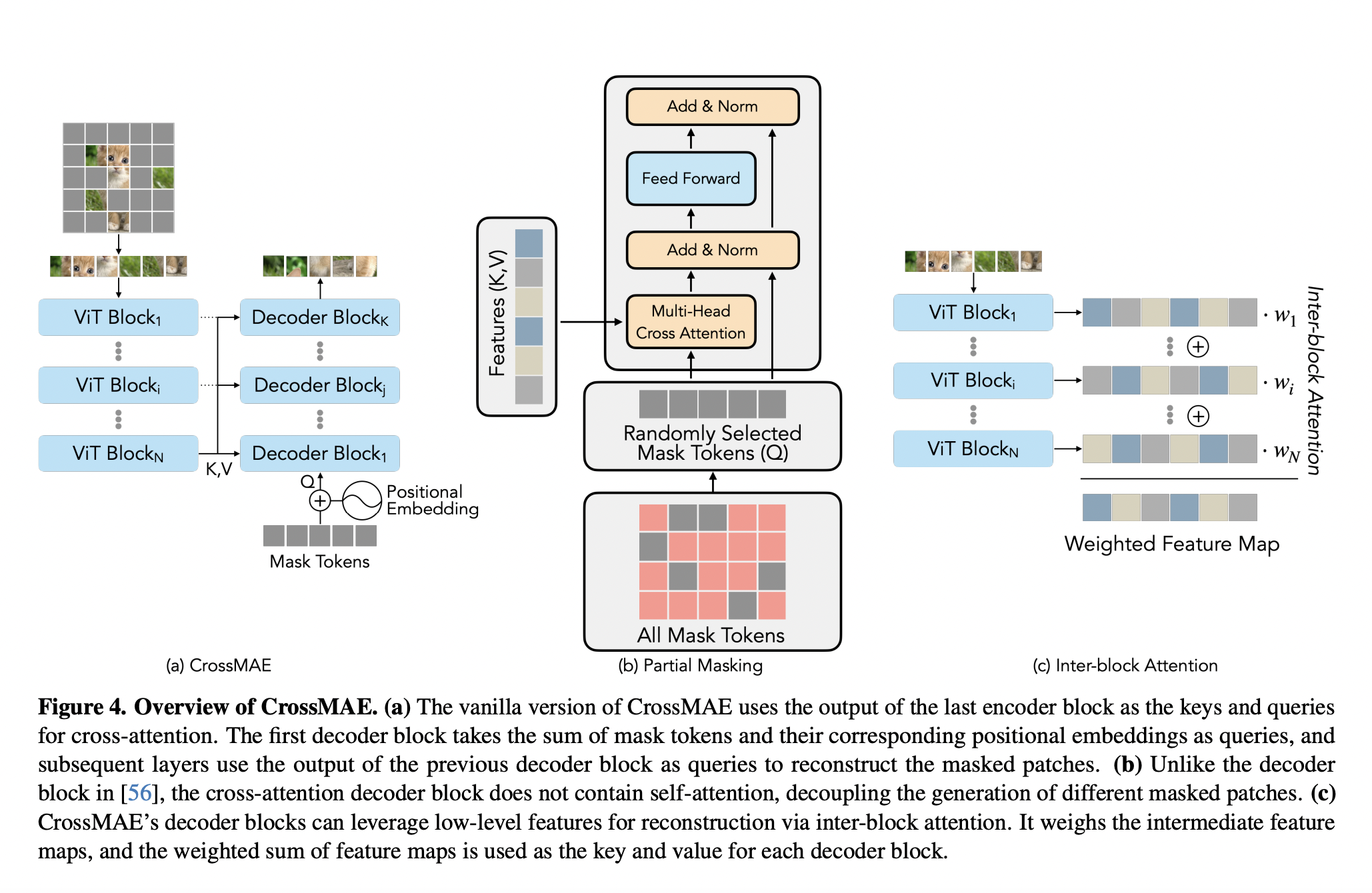
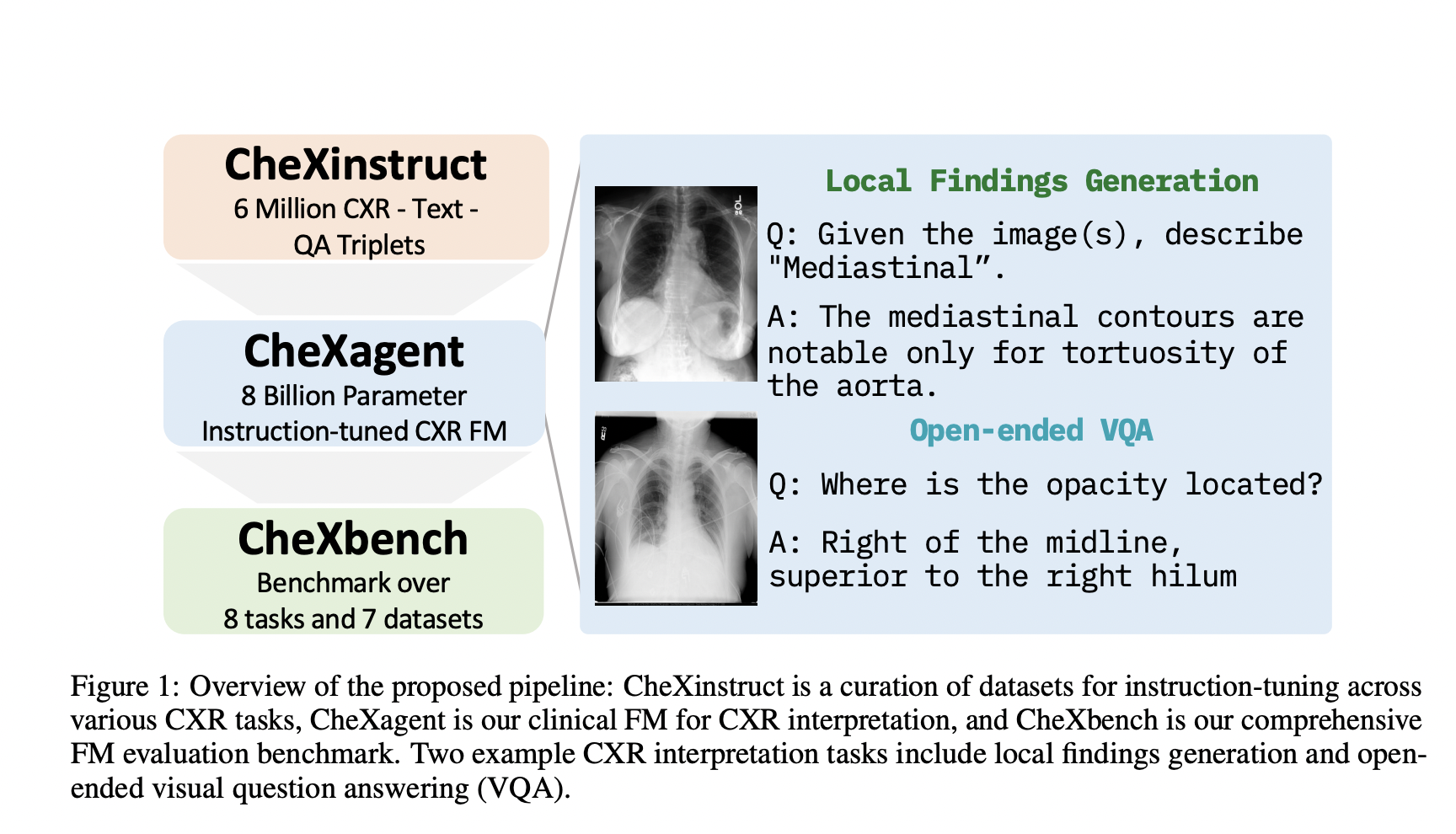
Large-scale pre-trained vision-language models, exemplified by CLIP (Radford et al., 2021), exhibit remarkable generalizability across diverse visual domains and real-world tasks. However, their zero-shot in-distribution (ID) performance faces limitations on certain downstream datasets. Additionally, when evaluated in a closed-set manner, these models often struggle with out-of-distribution (OOD) samples from novel classes, posing safety risks in…