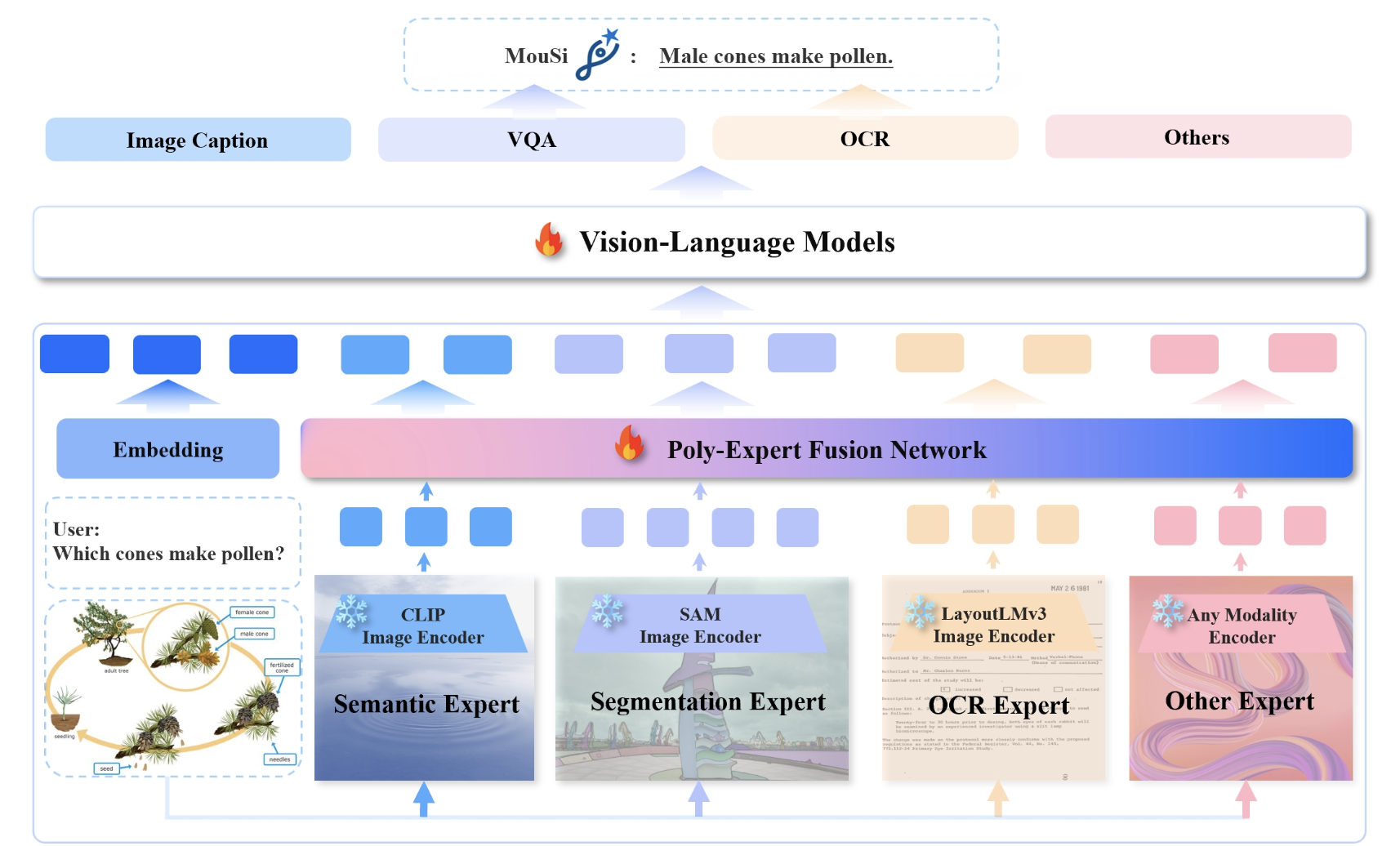
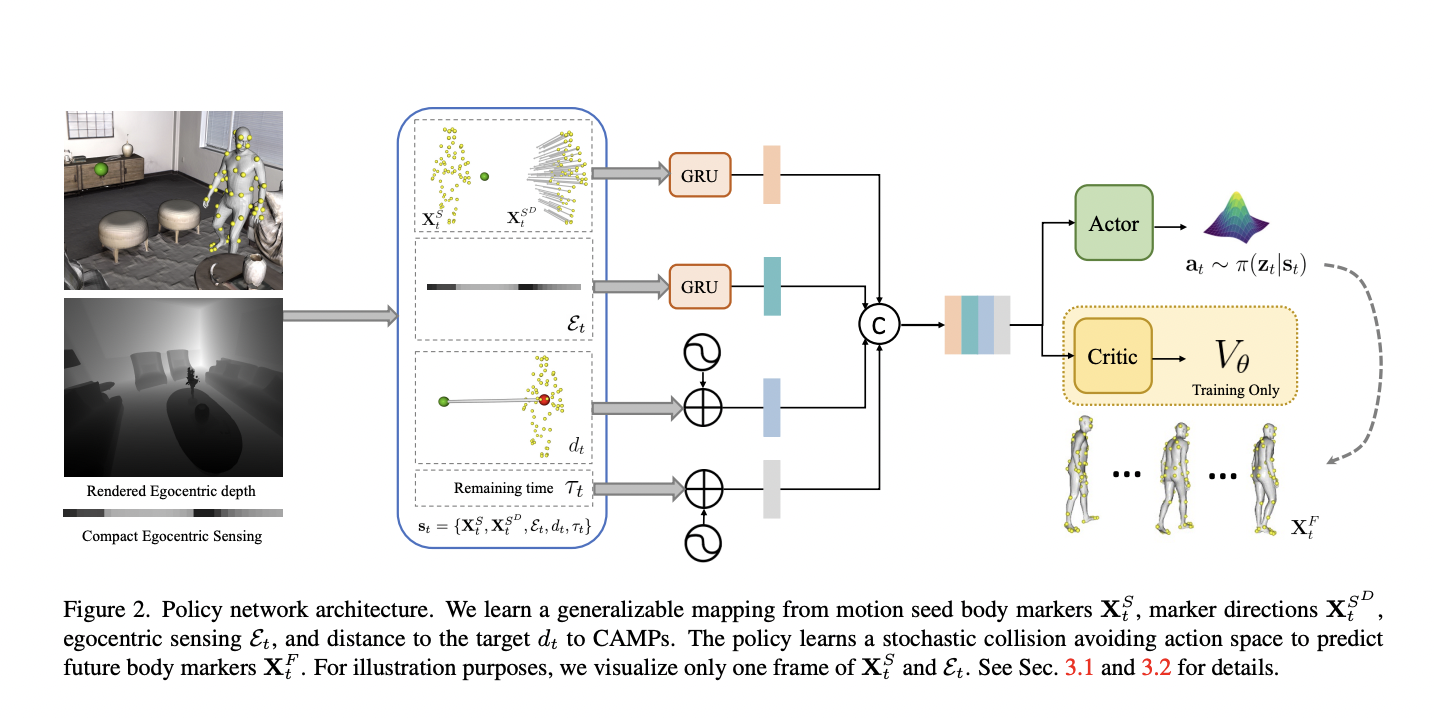
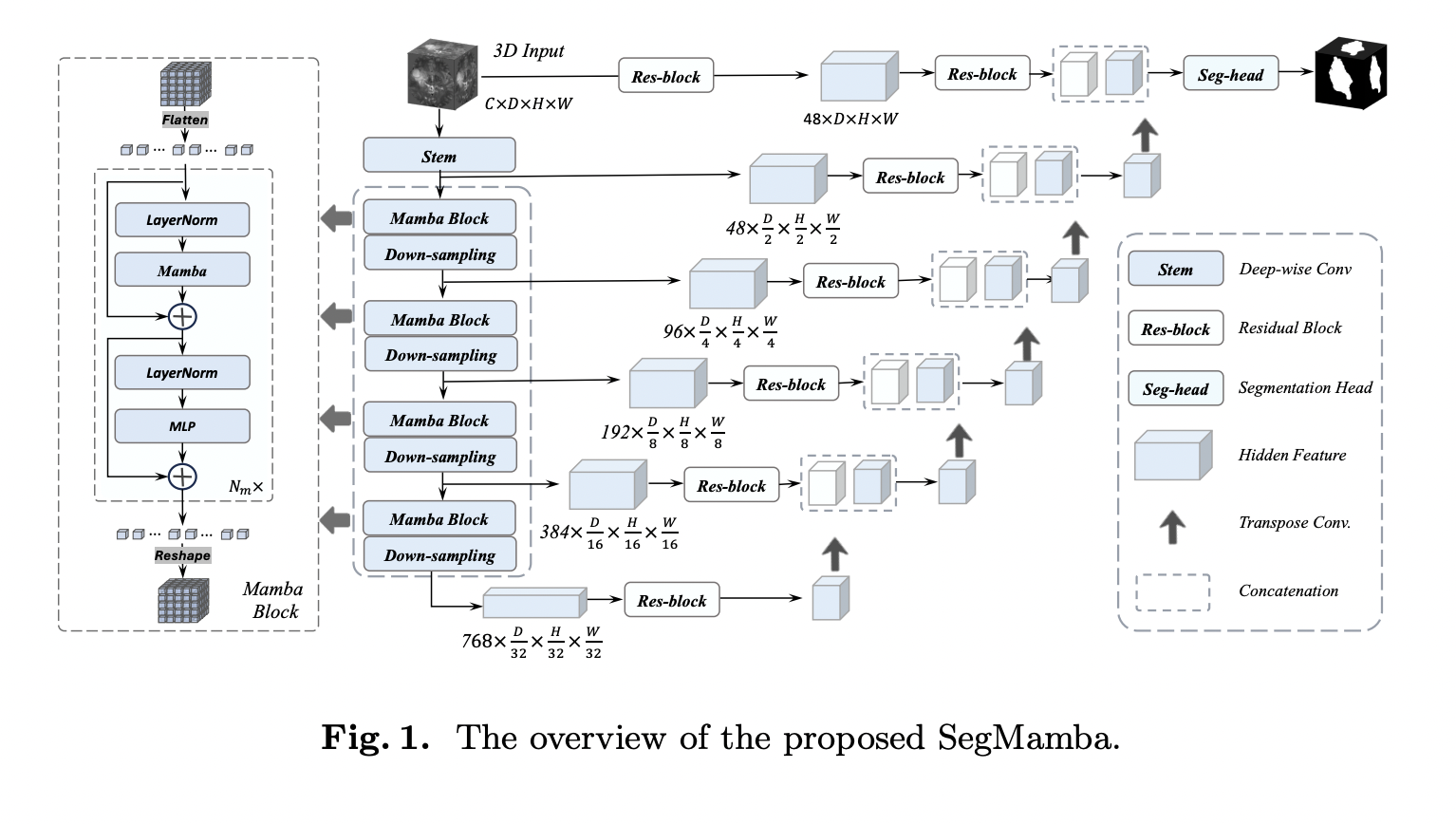
Current challenges faced by large vision-language models (VLMs) include limitations in the capabilities of individual visual components and issues arising from excessively long visual tokens. These challenges pose constraints on the model’s ability to accurately interpret complex visual information and lengthy contextual details. Recognizing the importance of overcoming these hurdles for improved performance and versatility,…