Image by Author | Canva
# Introduction
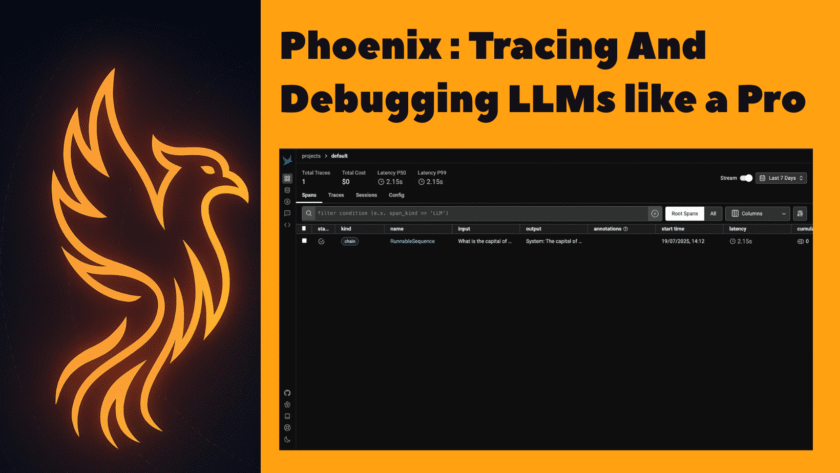
Traditional debugging with print() or logging works, but it’s slow and clunky with LLMs. Phoenix provides a timeline view of every…
Vision Language Models (VLMs) allow both text inputs and visual understanding. However, image resolution is crucial for VLM performance for processing text and chart-rich data. Increasing image resolution creates significant…
How Deep Think works: extending Gemini’s parallel “thinking time” Just as people tackle complex problems by taking the time to explore different angles, weigh potential solutions, and refine a final…
Estimated reading time: 5 minutes
Introduction
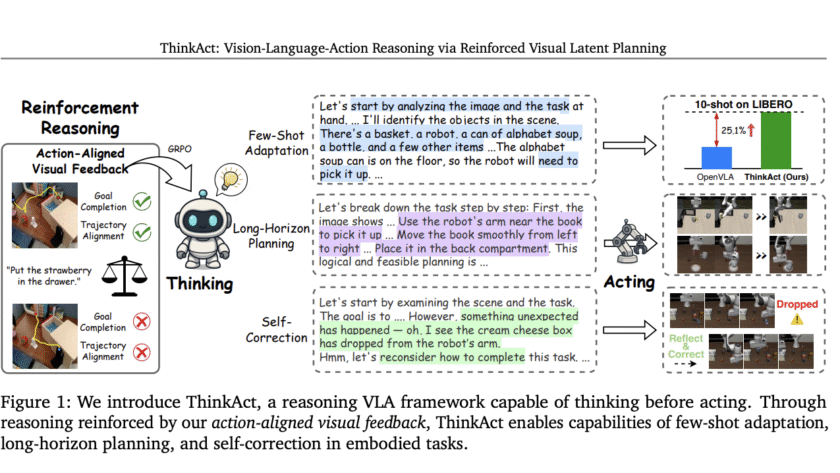
Embodied AI agents are increasingly being called upon to interpret complex, multimodal instructions and act robustly in…
Image by Author | Ideogram
# Introduction
From your email spam filter to music recommendations, machine learning algorithms power everything. But they don't have to be supposedly complex…
Embedding models act as bridges between different data modalities by encoding diverse multimodal information into a shared dense representation space. There have been advancements in embedding models in recent years,…
Micromobility solutions—such as delivery robots, mobility scooters, and electric wheelchairs—are rapidly transforming short-distance urban travel. Despite their growing popularity as flexible, eco-friendly transport alternatives, most micromobility devices still rely heavily…
Supply chains are the lifeblood of global commerce, yet they remain plagued by inefficiencies—delays, stockouts, overproduction, and unpredictable disruptions. Enter autonomous AI agents, the silent orchestrators now optimizing logistics with superhuman…
Image by Author | Canva
# Introduction
This is the second article in my beginner project series. If you haven’t seen the first one on Python, it’s worth…