Image by Author
# Introduction
While groupby().sum() and groupby().mean() are fine for quick checks, production-level metrics require more robust solutions. Real-world tables often involve multiple keys, time-series data,…
We gave our new C2S-Scale 27B model a task: Find a drug that acts as a conditional amplifier, one that would boost the immune signal only in a specific “immune-context-positive”…
Image by Author
# Introduction
There are numerous tools for processing datasets today. They all claim — of course they do — that they’re the best and the…
Optical Character Recognition (OCR) is the process of turning images that contain text—such as scanned pages, receipts, or photographs—into machine-readable text. What began as brittle rule-based systems has evolved into…
Earlier this year, we mentioned that we're bringing computer use capabilities to developers via the Gemini API. Today, we are releasing the Gemini 2.5 Computer Use model, our new specialized…
Image by Author
LinkedIn is often the first place you look for job opportunities. The same applies to recruiters when searching for suitable candidates. By optimizing your LinkedIn profile,…
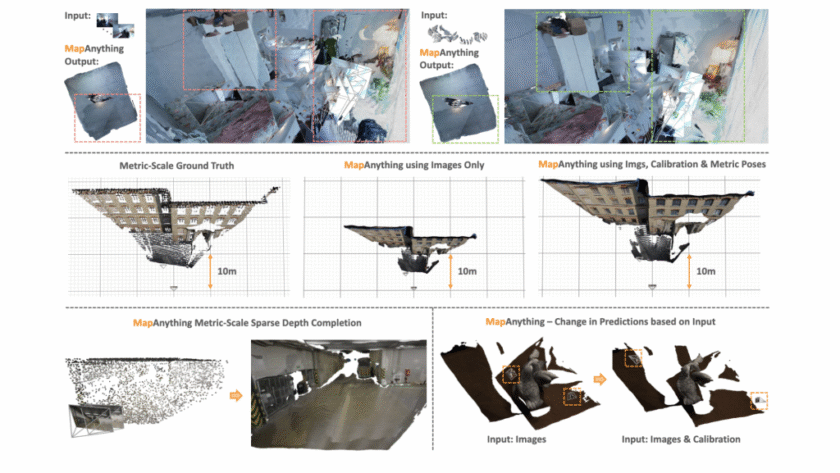
A team of researchers from Meta Reality Labs and Carnegie Mellon University has introduced MapAnything, an end-to-end transformer architecture that directly regresses factored metric 3D scene geometry from images and…