Image by Author | Canva
# Introduction
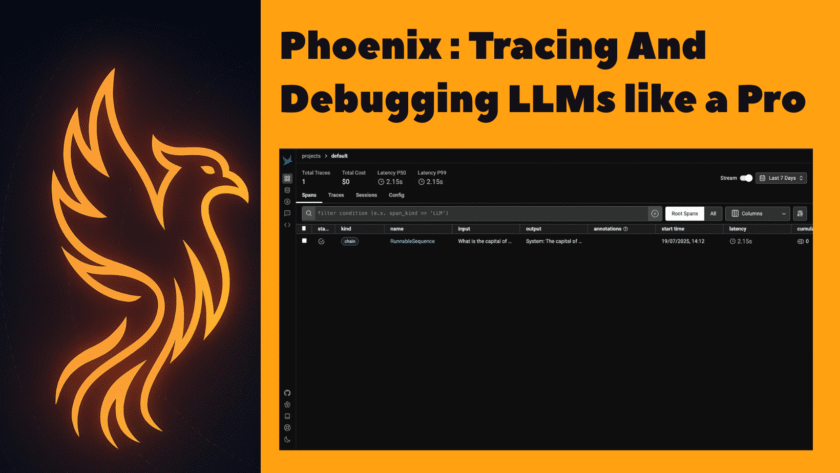
Traditional debugging with print() or logging works, but it’s slow and clunky with LLMs. Phoenix provides a timeline view of every step, prompt, and response inspection, error detection with retries, visibility into latency and costs, and a complete visual understanding of your app. Phoenix by Arize…