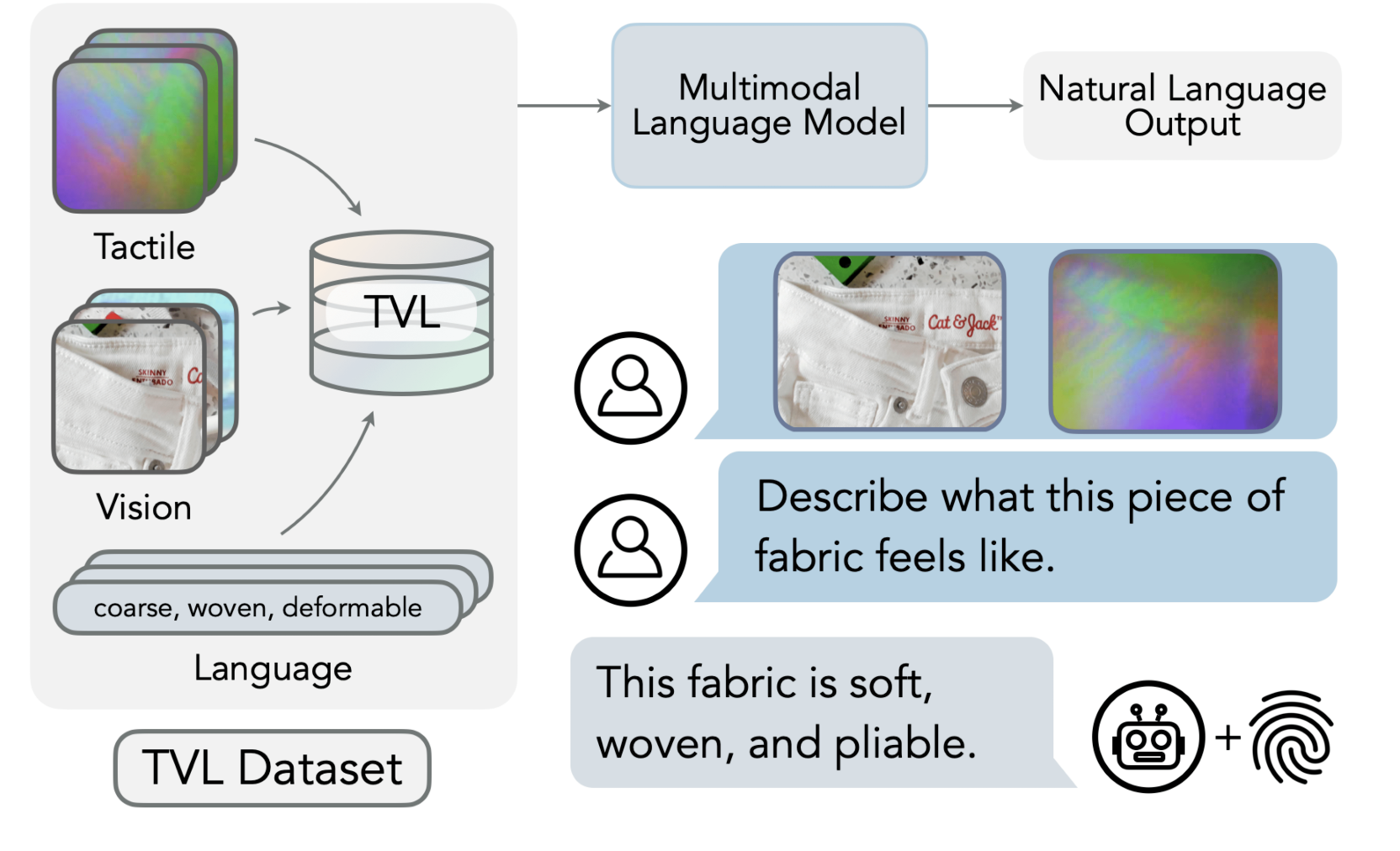
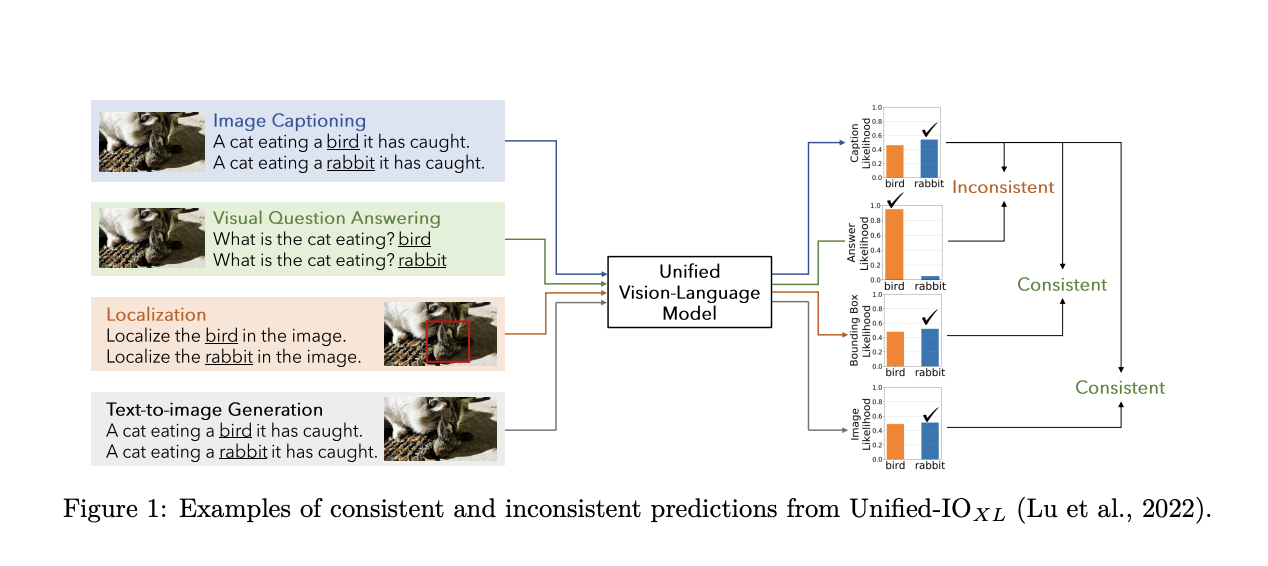
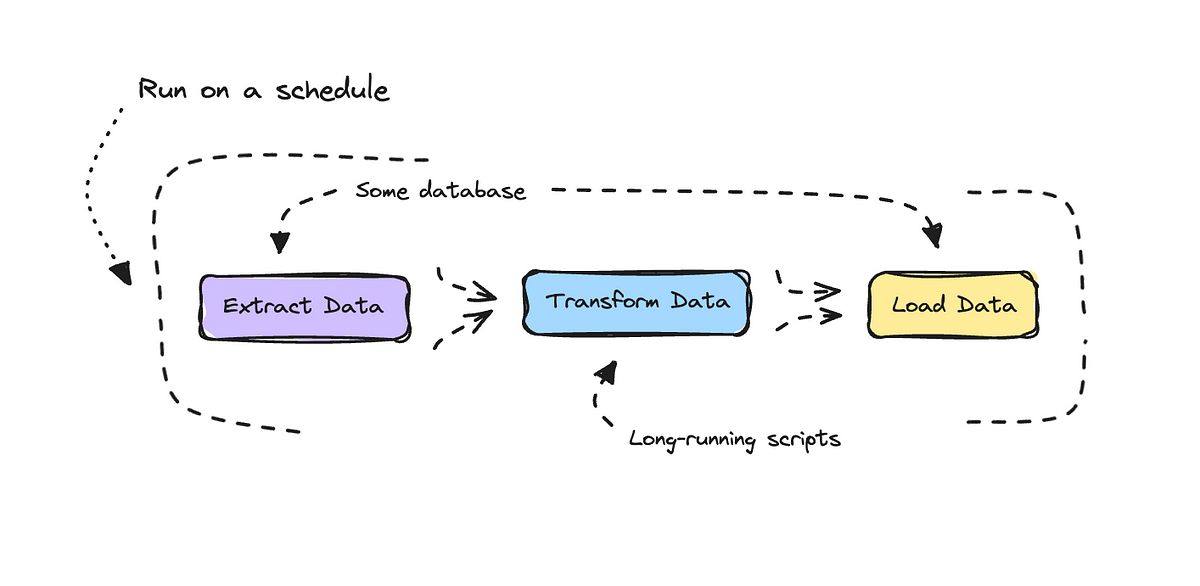
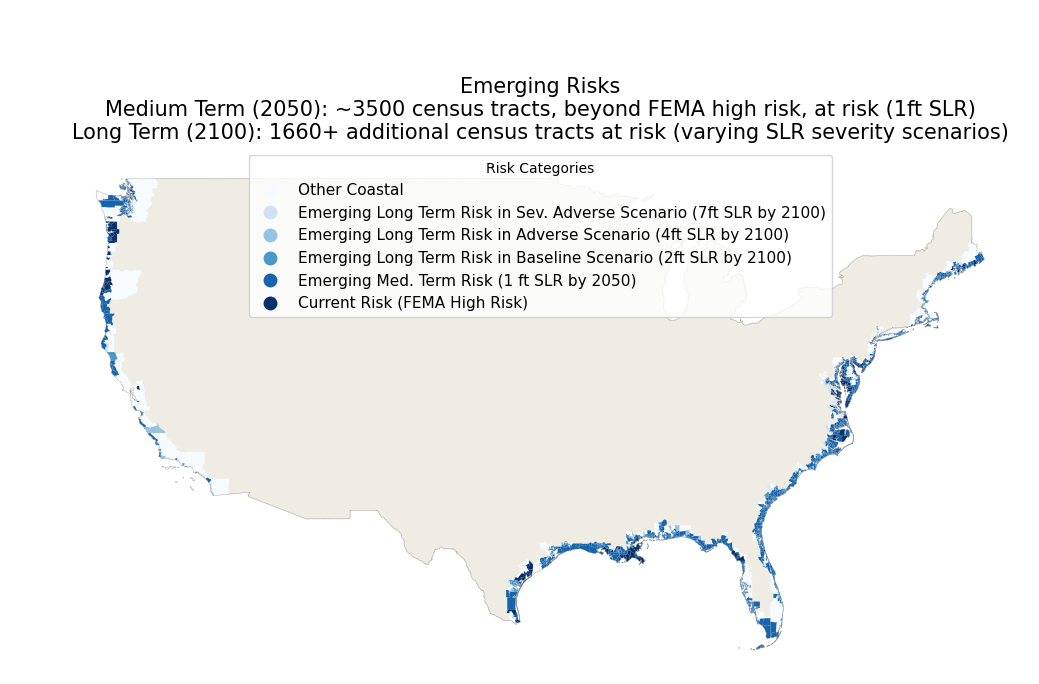
Lawyers often grapple with many documents in the dynamic legal world where every second counts, and information is the key to success. The sheer volume of paperwork, from contracts and court pleadings to discovery documents and case research, can be overwhelming. The legal landscape is evolving rapidly, and the need for efficient document management solutions…