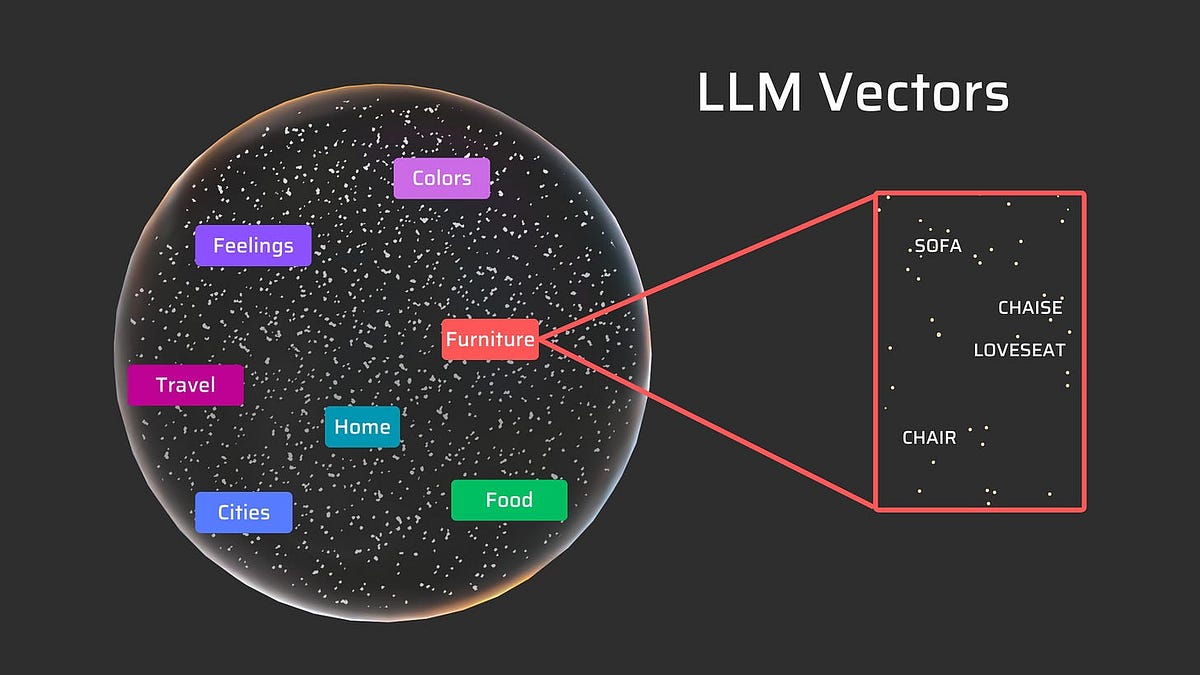
Let’s implement a regression example where the aim is to train a network to predict the value of a node given the value of all other nodes i.e. each node has a single feature (which is a scalar value). The aim of this example is to leverage the inherent relational information encoded in the graph…