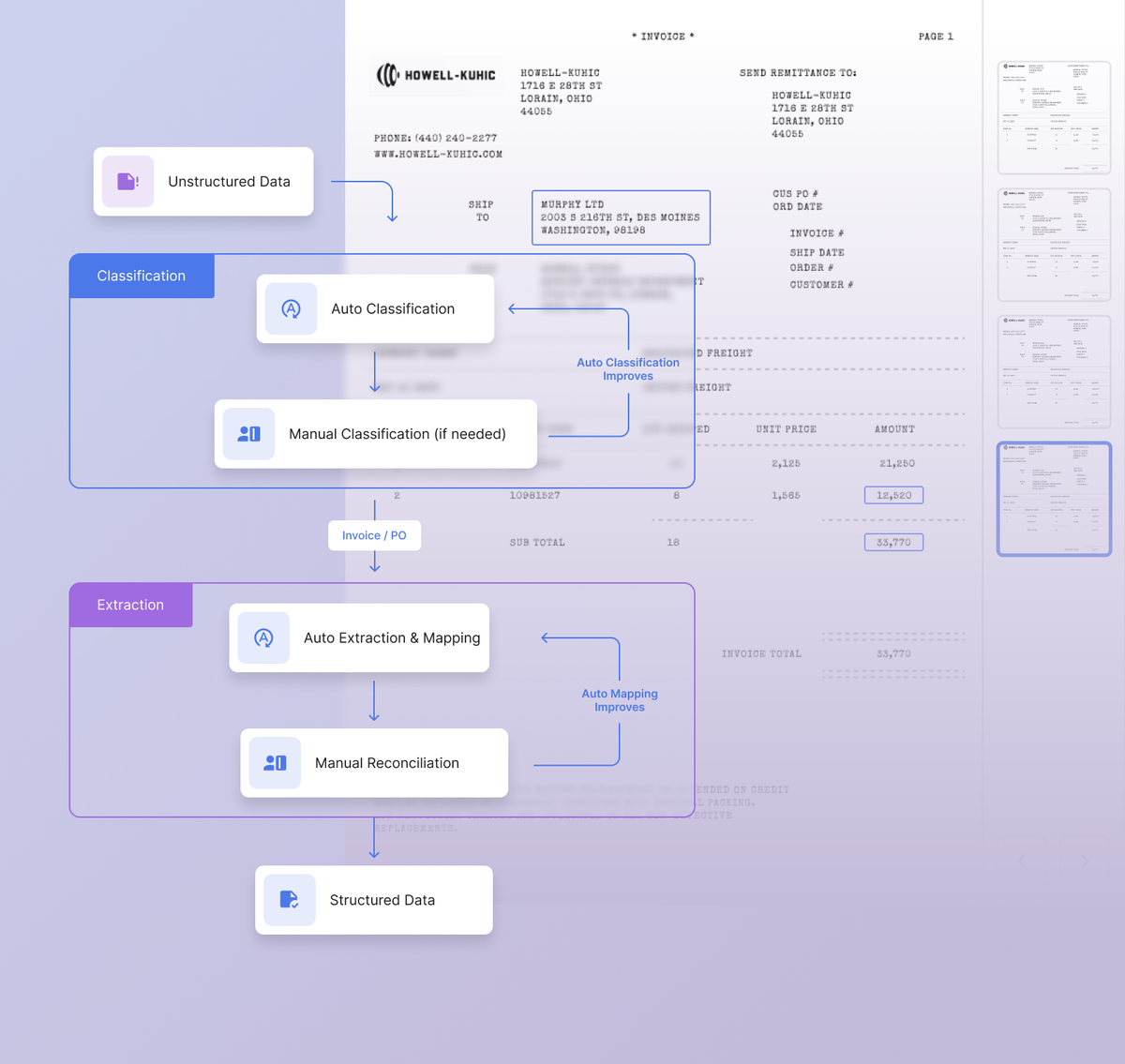
Six simple techniques you can apply in real life The first part of this series discussed the growing need for problem-solving skills. As more of our world is automated with AI these skills are more important than ever. This article continues to outline practical strategies for solving any problem. Three more techniques are outlined below…