
In a recent move, Microsoft’s Azure AI platform has expanded its range by introducing two advanced AI models, Llama 2 and GPT-4 Turbo with Vision. This addition marks a significant expansion in the platform’s AI capabilities.
The team at Microsoft Azure AI recently announced the arrival of Llama 2, a set of models developed by…
admin
Company
Published
…

1. Choosing a Chatbot As simple as this one may sound, it is far from a trivial question. The options are manifold and include choosing to build your own chatbot using open-sourced code.[1] Using one of the gazillion chatbot APIs offered on the market, that allow you the simplest and quickest ready-set-go set-up.[2] Finetuning your…

Introduction Data is the lifeblood of modern marketing and lead generation. Companies implementing data-driven marketing enjoy a sixfold higher likelihood of year-over-year profitability, providing a distinct advantage over the competition. Marketing teams can potentially generate high-quality leads from many sources for their marketing and customer reach activities. These include social media sites, as well as…
The days of stuffed filing cabinets and banker boxes full of loose paperwork are behind us. In many ways, we’re even past the era that centralized company information within a series of Excel workbooks and PDFs shared by file-transfer protocol. But today presents a range of document management challenges, no matter how far we’ve come.…

Image by Author
New open source models like LLaMA 2 have become quite advanced and are free to use. You can use them commercially or fine-tune them on your own data to develop specialized versions. With their ease of use, you can now run them locally on your own device.
In this post,…
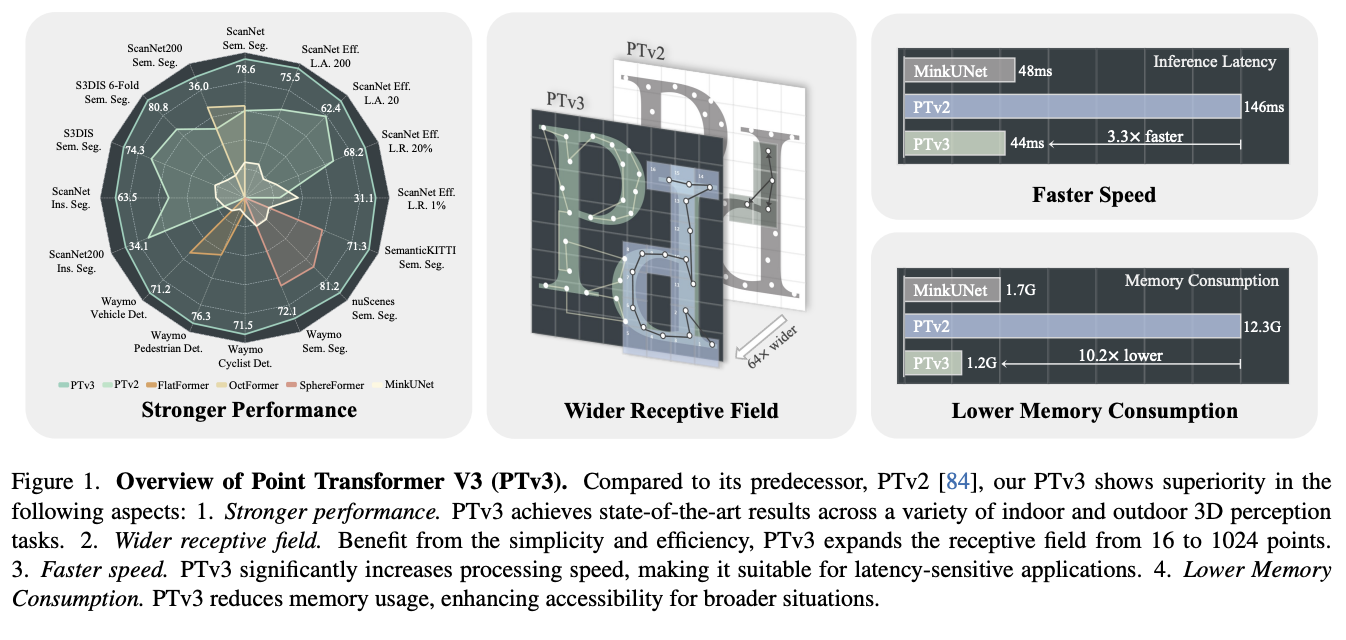
In the digital transformation era, the three-dimensional revolution is underway, reshaping industries with unprecedented precision and depth. At the heart of this revolution lies point cloud processing – an innovative approach that captures the intricacies of our physical world in a digital format. From autonomous vehicles navigating complex terrains to architects designing futuristic structures, point…

AlphaFold unlocks a decade of data within minutes that can help beat antibiotic resistance Most people who have access to a modern healthcare system would not consider a disease like bubonic plague to be a threat. Such bacterial infections are usually dealt with easily through modern antibiotics. Yet antibiotic resistance, where bacteria evolve the ability…

Social media spam as a case study Photo by Nong on UnsplashDisclaimer: the examples in this post are for illustrative purposes and are not commentary on any specific content policy at any specific company. All views expressed in this article are mine and do not reflect my employer. Why is there any spam on social…

Image by Editor
Data science is a field that has grown tremendously in the last hundred years because of advancements made in the field of computer science. With computer and cloud storage costs getting cheaper, we are now able to store copious amounts of data at a very low cost compared to a…