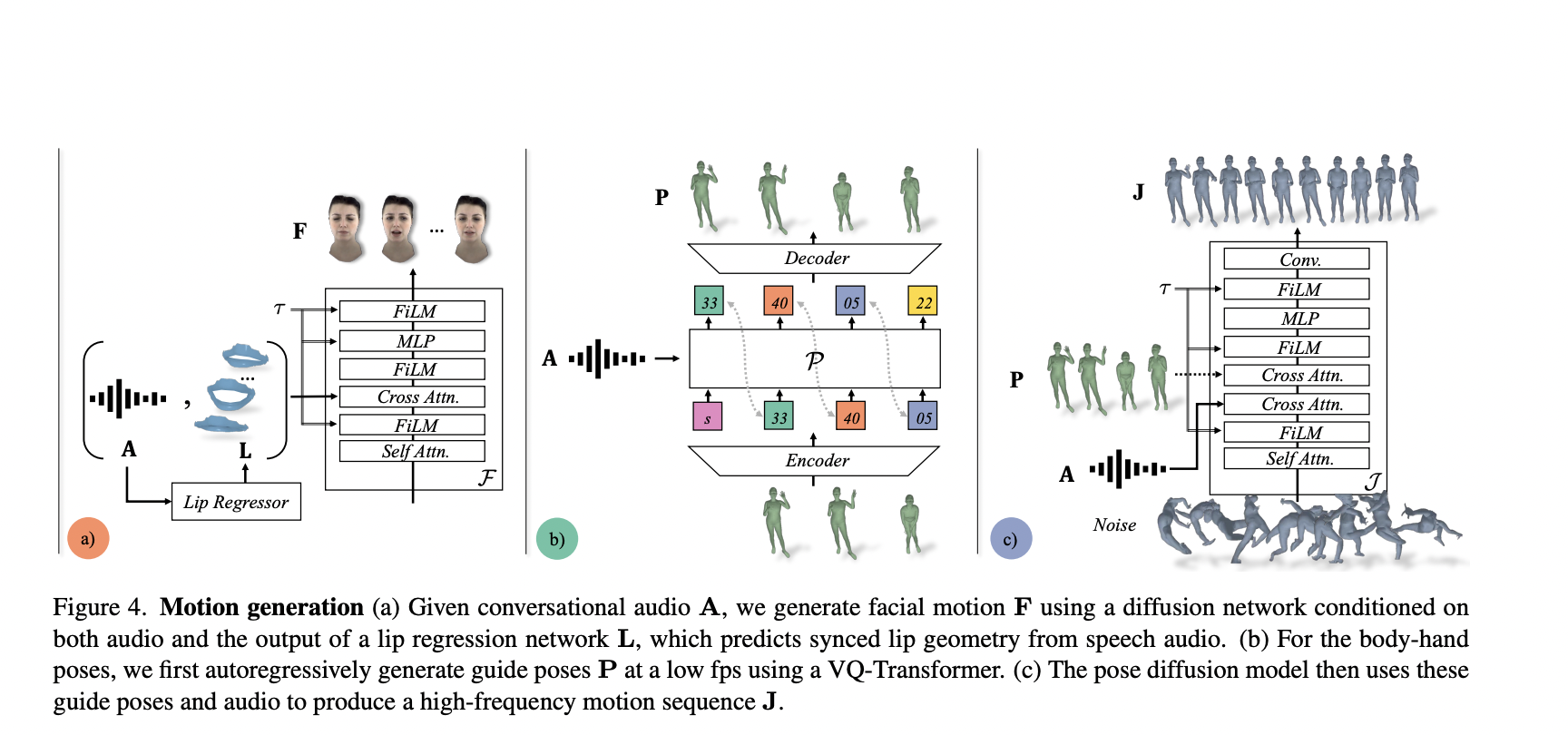
Avatar technology has become ubiquitous in platforms like Snapchat, Instagram, and video games, enhancing user engagement by replicating human actions and emotions. However, the quest for a more immersive experience led researchers from Meta and BAIR to introduce “Audio2Photoreal,” a groundbreaking method for synthesizing photorealistic avatars capable of natural conversations.
Imagine engaging in a telepresent…