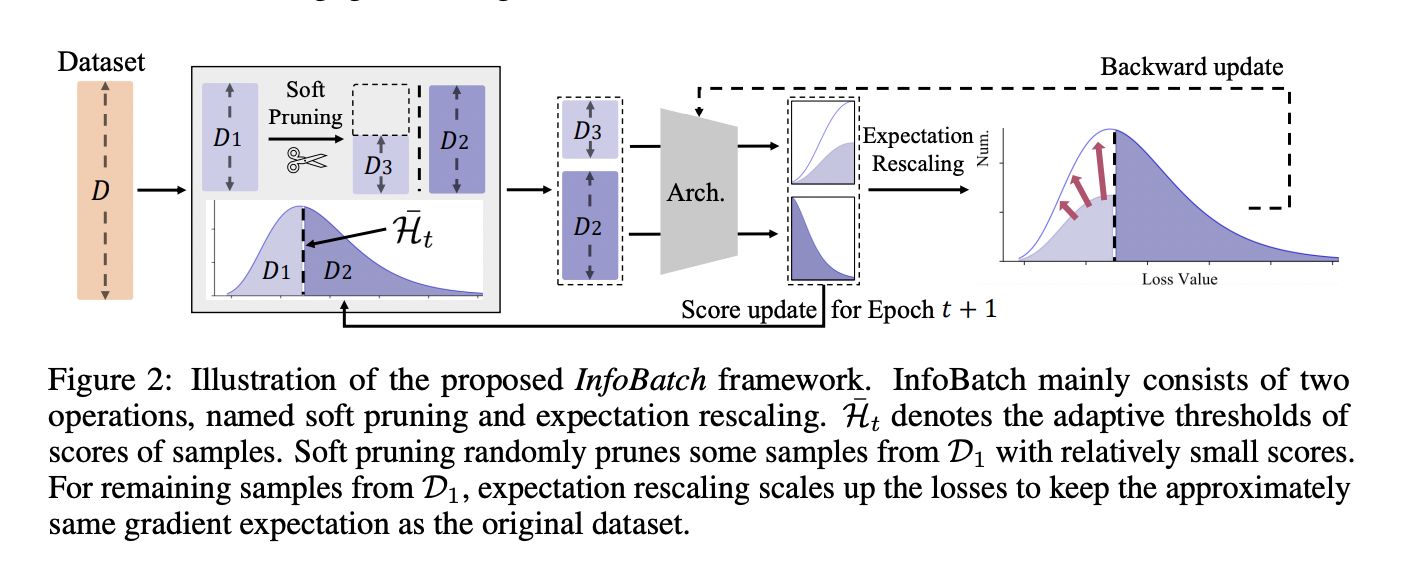
The question is not anymore whether we can solve the problem with AI but to what extent it returns sustainable and reliable results. Good craftsmanship, governance, ethics, and education on AI are what we need now. Photo by Karan Suthar on UnsplashSince I was a kid, I have always been intrigued and interested in new…