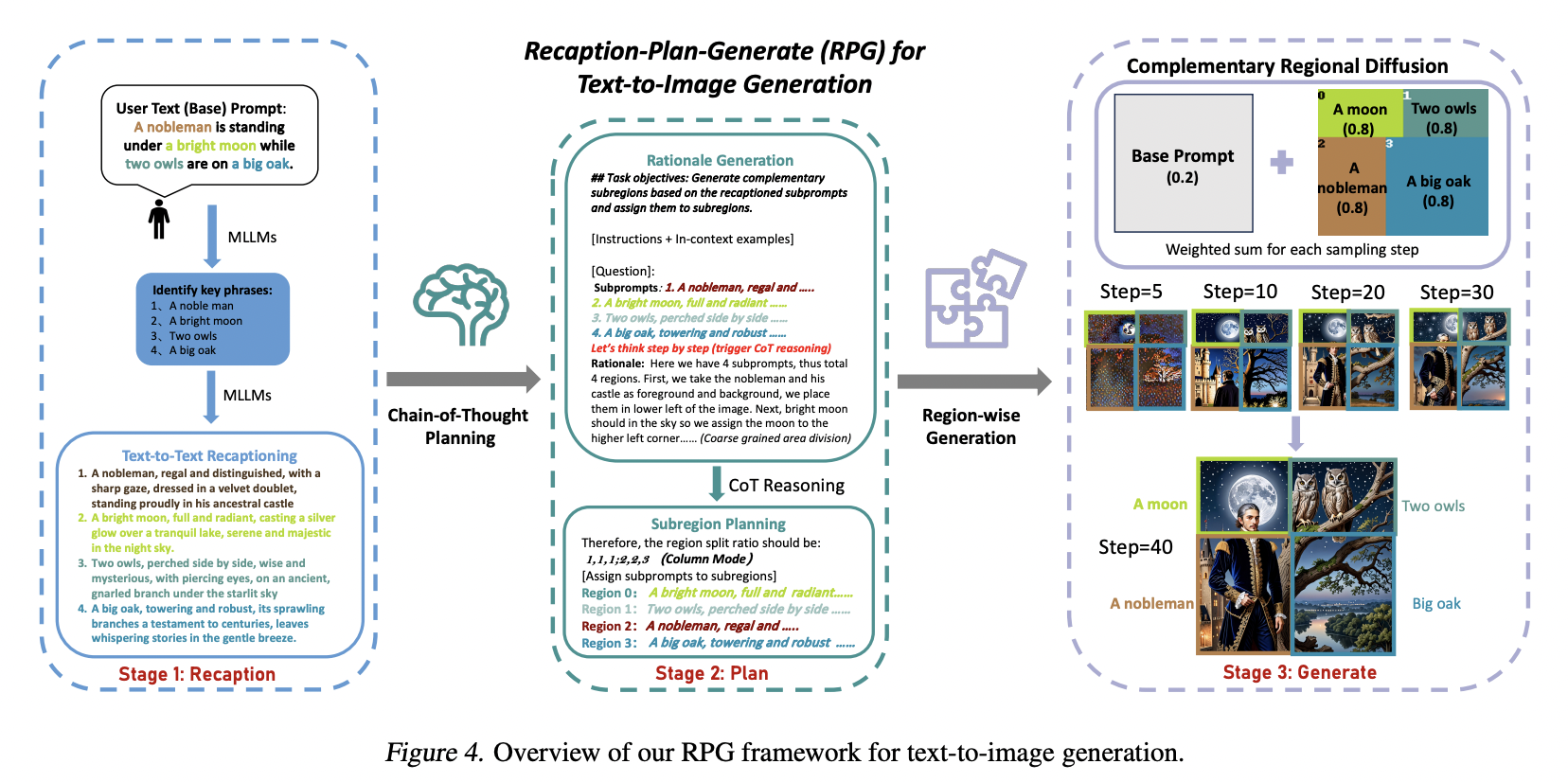
Image by Author
There’s one single lesson I learned from using ChatGPT. It’s wonderfully helpful in data science, but you must scrutinize everything it outputs. It’s great for some tasks and can do them very quickly and accurately. For some other tasks, it’s good enough, and you’ll have to prompt it several times.…